3、资源设置
“资源设置”是智能体应用构建过程中至关重要的底层能力扩展模块,该模块主要用于为智能体挂载外部数据源、配置专属的大语言模型(LLM)以及启用多模态交互能力。通过科学合理地分配和配置这些底层资源,开发者能够打破大模型预训练数据的认知局限,赋予智能体处理特定领域知识、动态查询业务数据库以及进行拟真语音交互的高阶能力,从而全方位提升智能体的业务适用性与智能化水平。
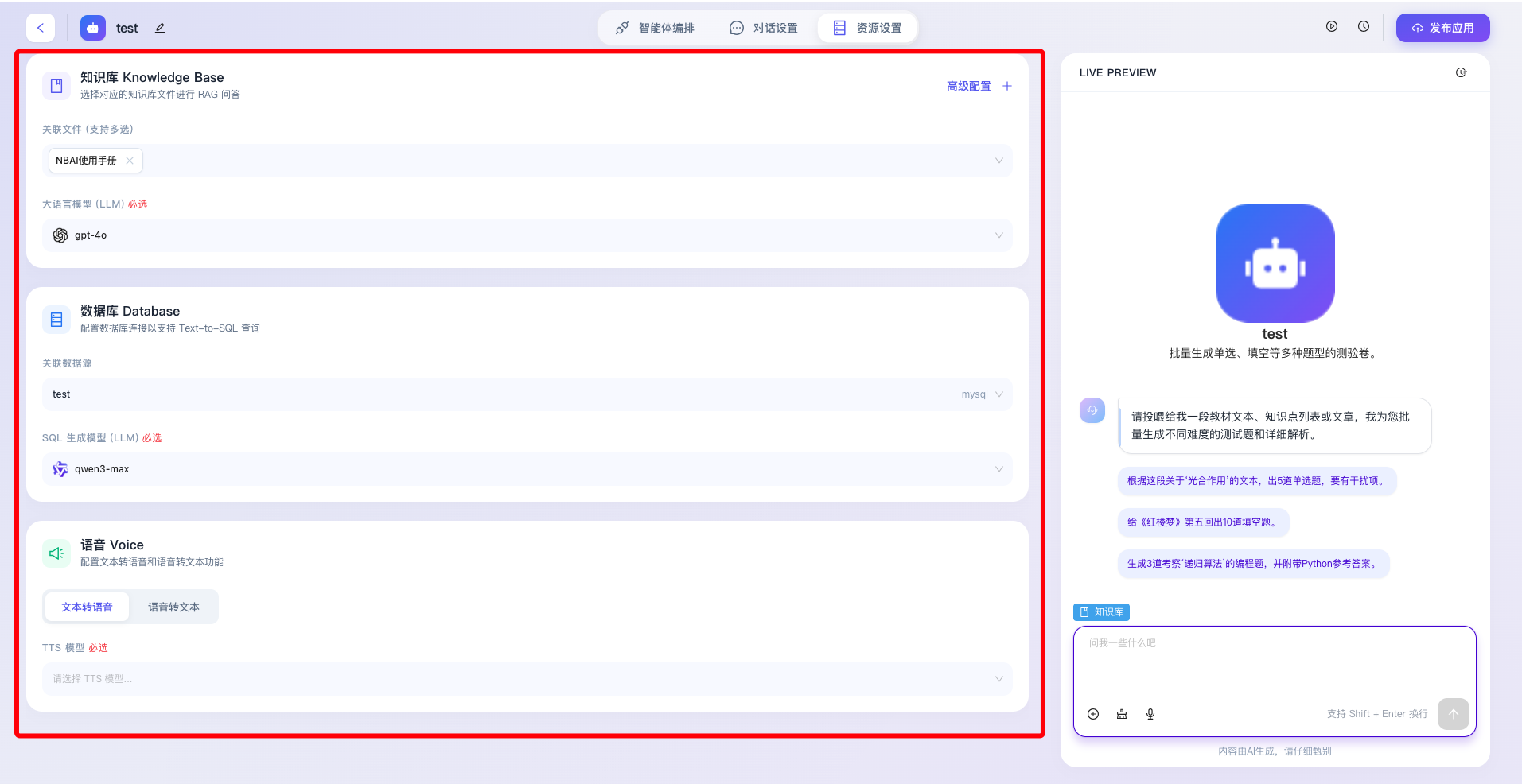
3.1 知识库配置
该部分主要用于构建基于检索增强生成(RAG, Retrieval-Augmented Generation)架构的专业问答能力,纯粹的大语言模型往往存在知识盲区或“幻觉”现象,通过配置知识库,开发者可以将企业内部的文档、操作手册、行业规范等私有化资产转化为智能体的“外挂大脑”。
包含的配置功能点如下:
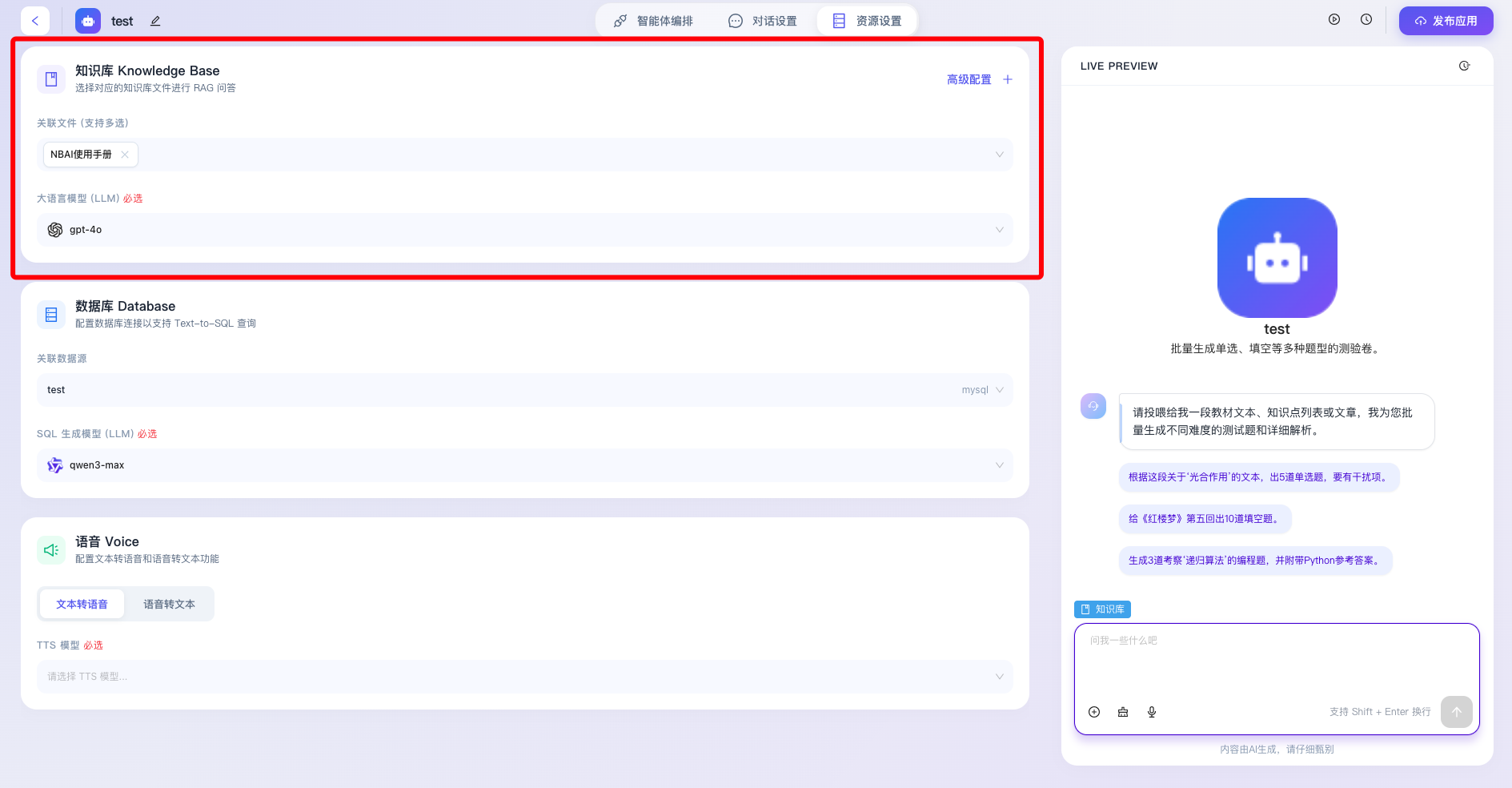
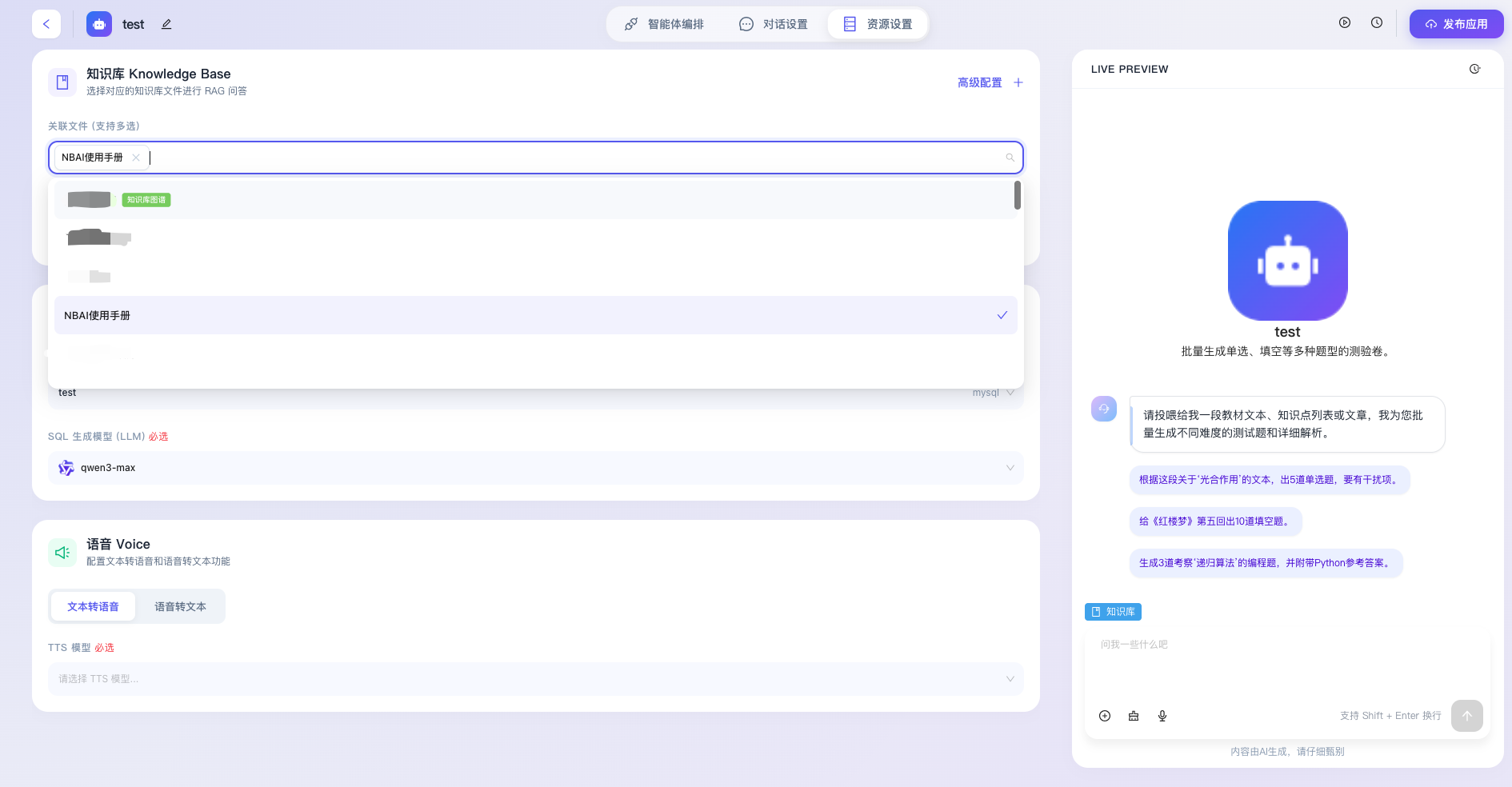
- 关联文件(支持多选):用于灵活挂载平台内已上传的各类知识资产,支持通过下拉框同时选中多个文档(至多支持5个),构建复合型的知识语料网络,确保智能体在执行内容检索时能覆盖更广泛、更全面的参考面。
- 大语言模型(LLM)必选:用于指定负责处理知识库检索召回结果并生成最终自然语言回复的核心推理模型(如图中当前选中的 qwen3-max)。作为归纳与总结的引擎,该选项为系统强制必填项,开发者可根据具体业务对推理逻辑严密性和响应速度的考量,灵活切换底层大模型基座。
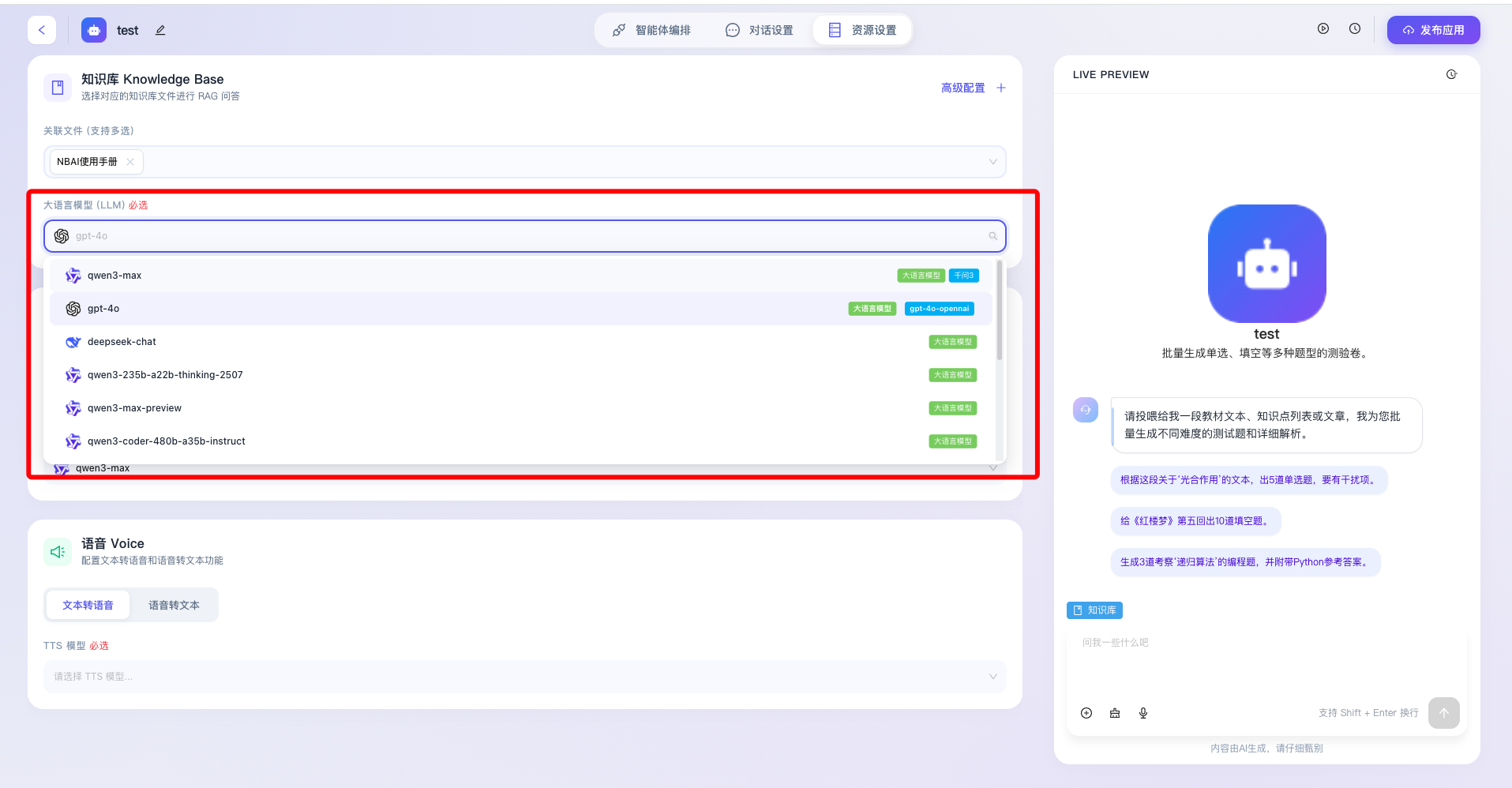
3.1.1 高级配置
“知识库高级设置”是平台为开发者提供的用于深度定制检索增强生成(RAG, Retrieval-Augmented Generation)底层逻辑与召回策略的核心调优工作台,在面对复杂的企业级非结构化数据或高精度的垂直领域问答场景时,仅依靠系统的默认检索配置往往难以达到理想的准确率与业务预期。
通过配置“高级设置”,开发者能够细颗粒度地掌控从用户查询解析、多路召回引擎、结果精排到最终输出兜底形态的每一个关键环节,从而在算力成本控制的前提下,显著提升智能体回答的命中率、相关性以及终端用户的信赖感。
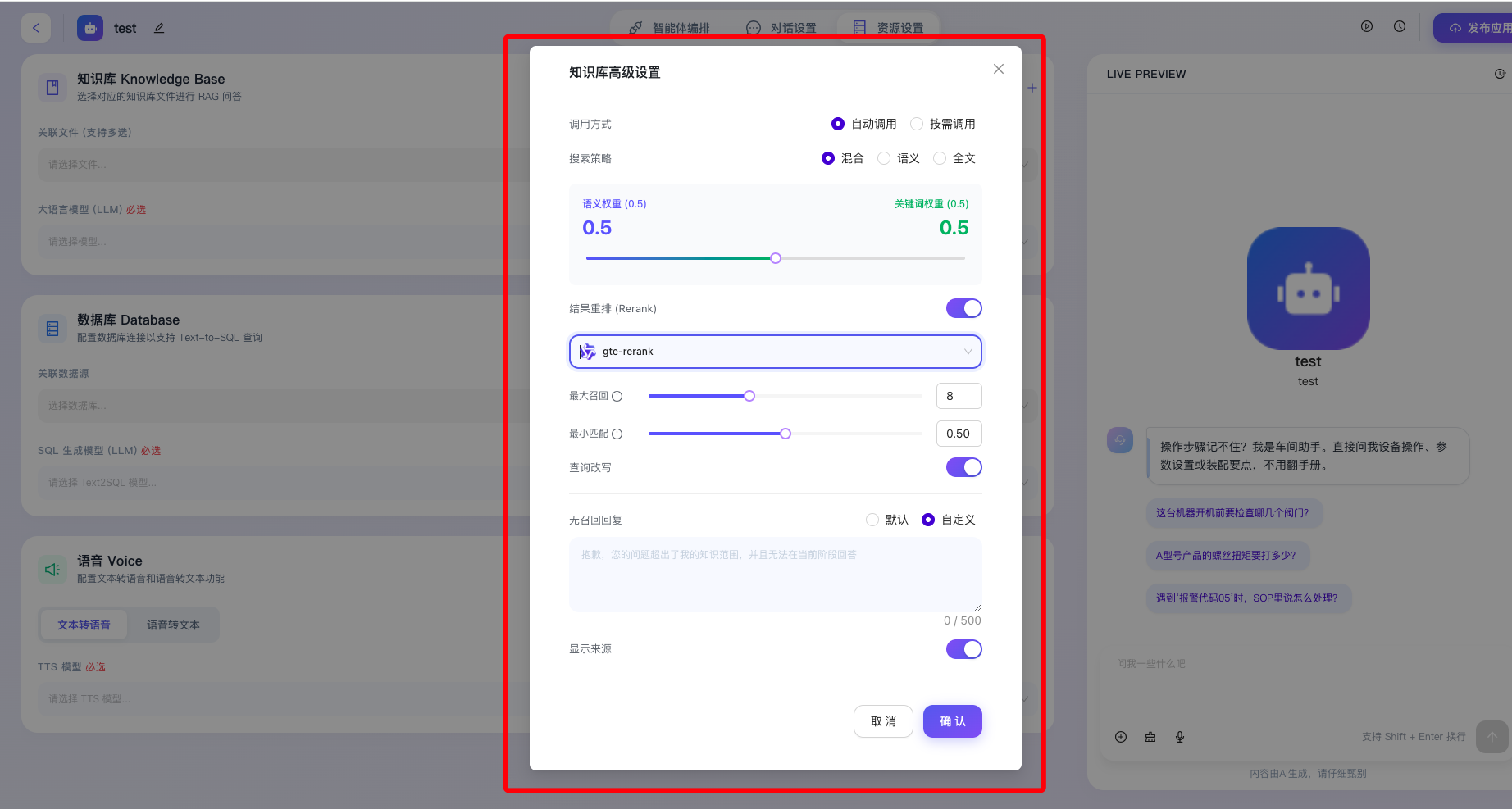
包含的配置功能点如下:
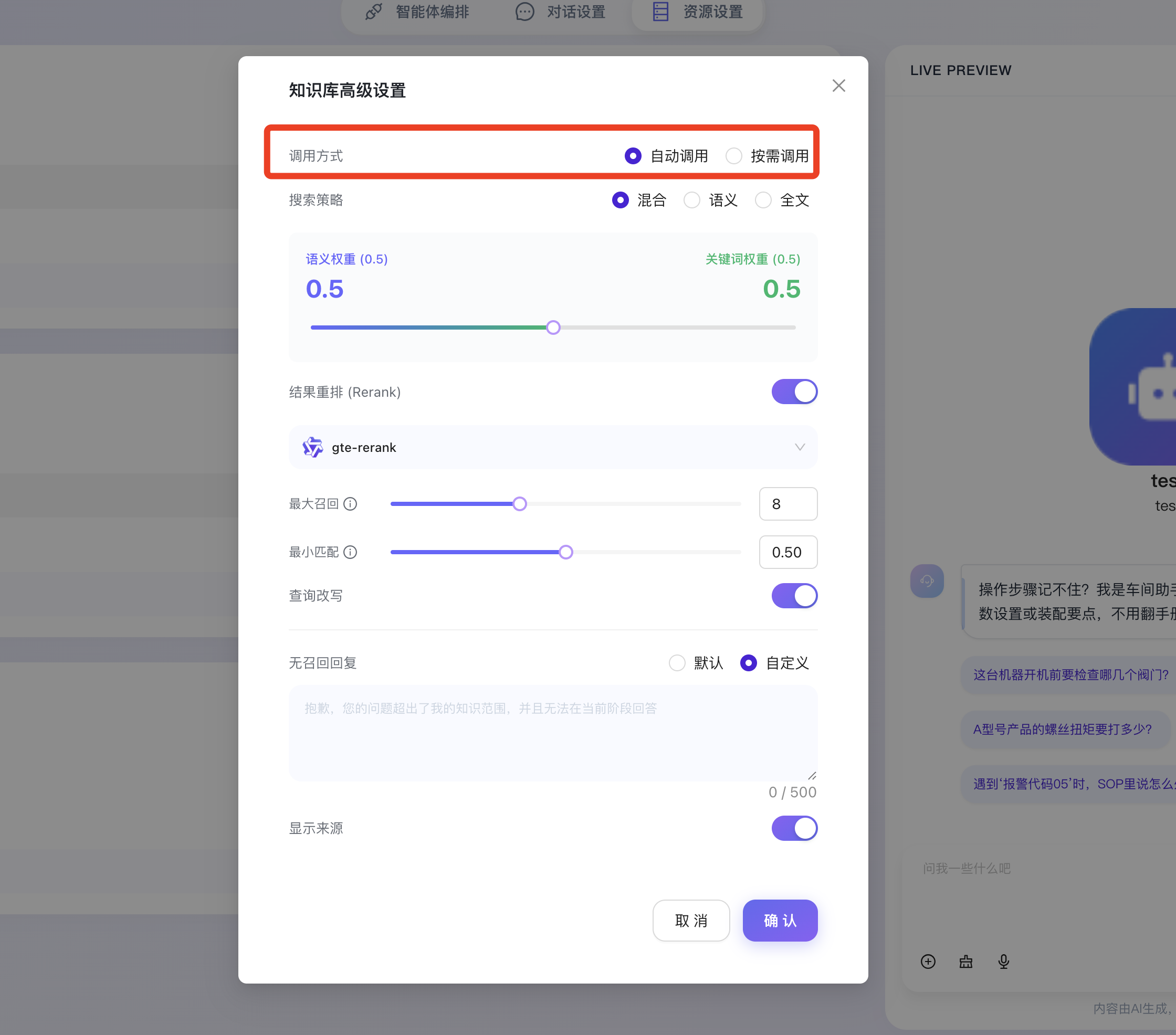
- 调用方式:用于设定知识库被激活的触发机制。
- 自动调用:将决策权交由大模型,模型会根据用户的当前提问及上下文语义,自主判断是否需要外挂知识库进行辅助查询,适用于绝大多数通用问答场景,灵活性强。
- 按需调用:通常用于需要严格控制数据流向或特定业务流程内强制/禁止查询知识库的场景。
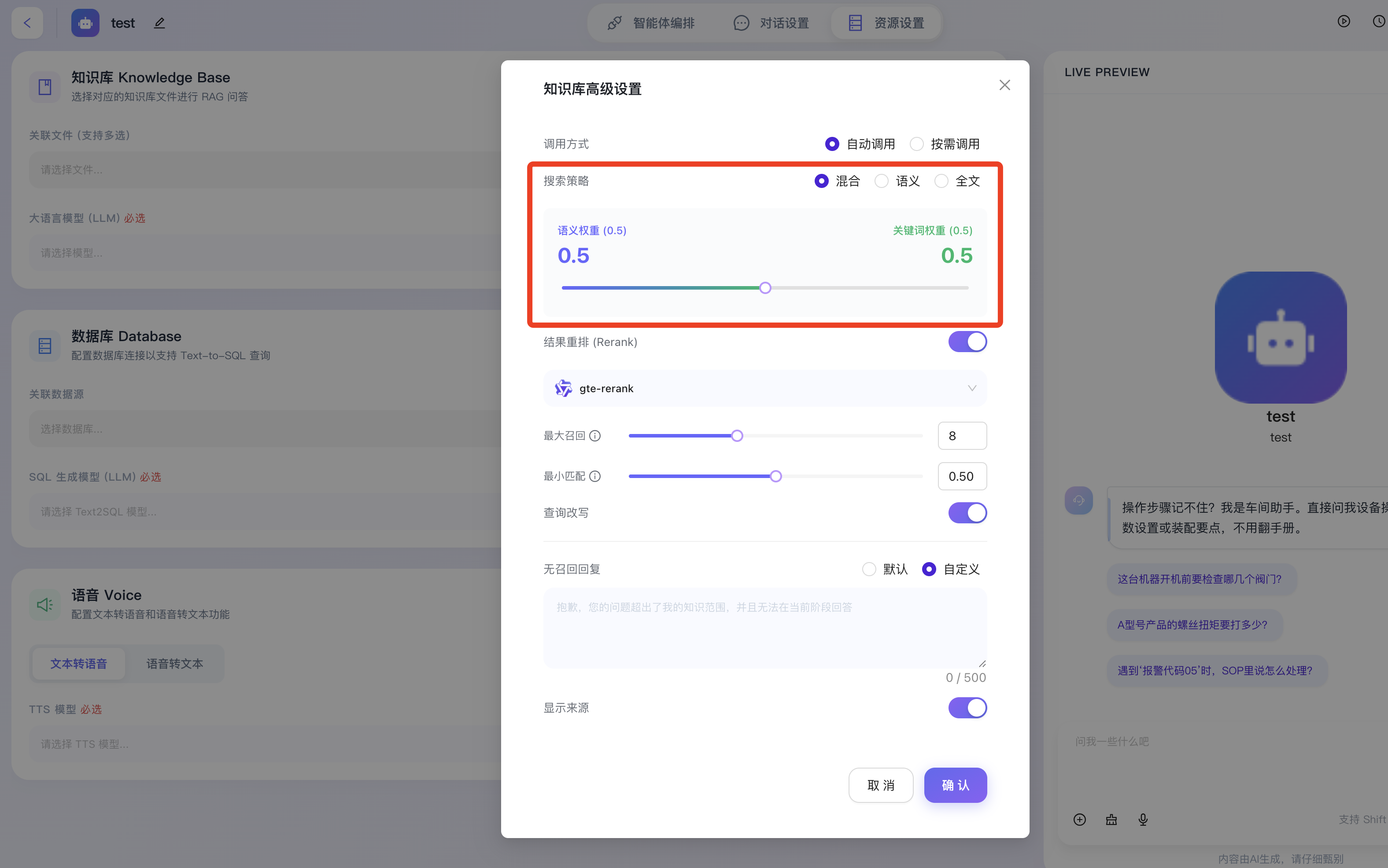
- 搜索策略:提供三种底层检索算法架构,以适配不同类型文档的提取需求:
- 混合:结合了基于深度学习的向量语义特征与传统关键词文本特征的双路召回优势,能应对最复杂的提问,综合命中效果最佳。
- 当选中“混合”策略时,系统提供可视化的滑块组件,允许开发者自定义“语义权重”与“关键词权重”的融合比例(如图中系统默认设定为各占 0.5)。开发者可根据私有知识库的具体文本分布特征,灵活向某一种检索方式倾斜。
- 语义:依赖文本向量化进行相似度计算,侧重理解用户意图背后的深层含义,即使字面不完全匹配也能找到相关段落。
- 全文:传统的倒排索引关键词匹配算法,适用于精准查找特定术语、产品型号或代码片段。
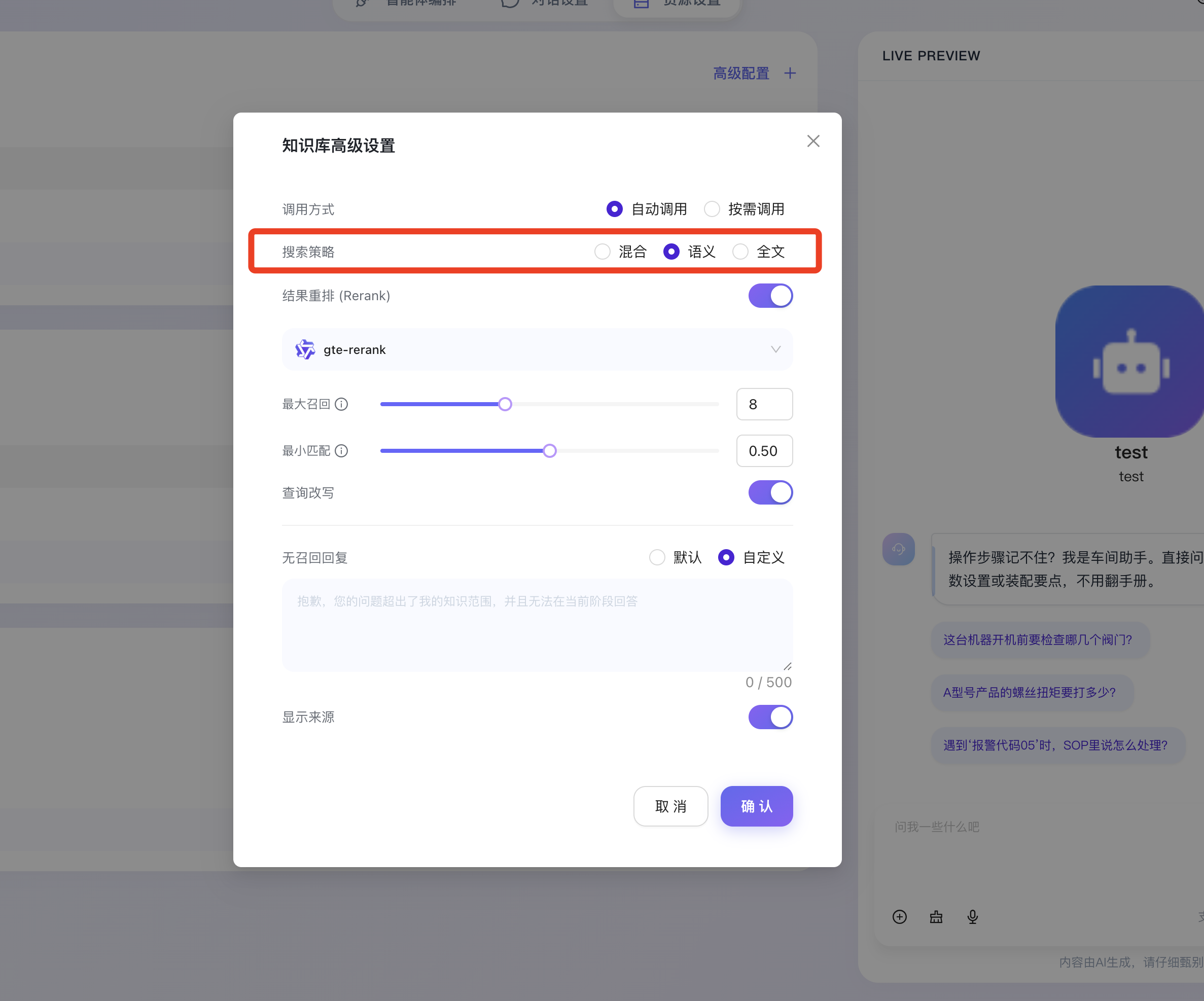
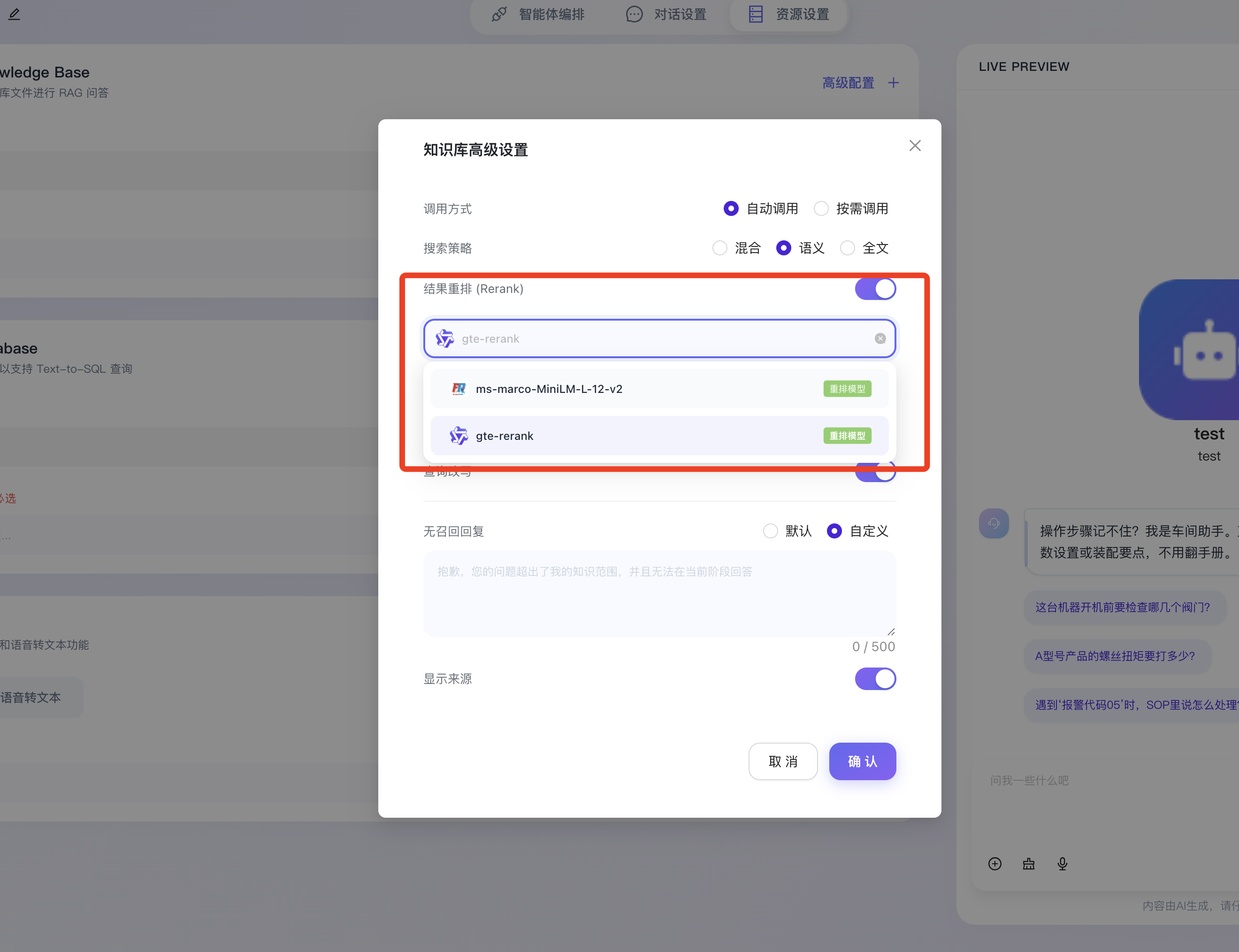
- 结果重排 (Rerank):开启后,支持指定专门的重排序交叉编码器模型(如图中选中的 gte-rerank)。重排序模型会对初步召回的多个文档切片进行更加细致的二次交叉计算与重新打分,有效解决初次粗排检索可能存在的排序不准问题,大幅提升 Top-K 结果与用户真实意图的契合度。
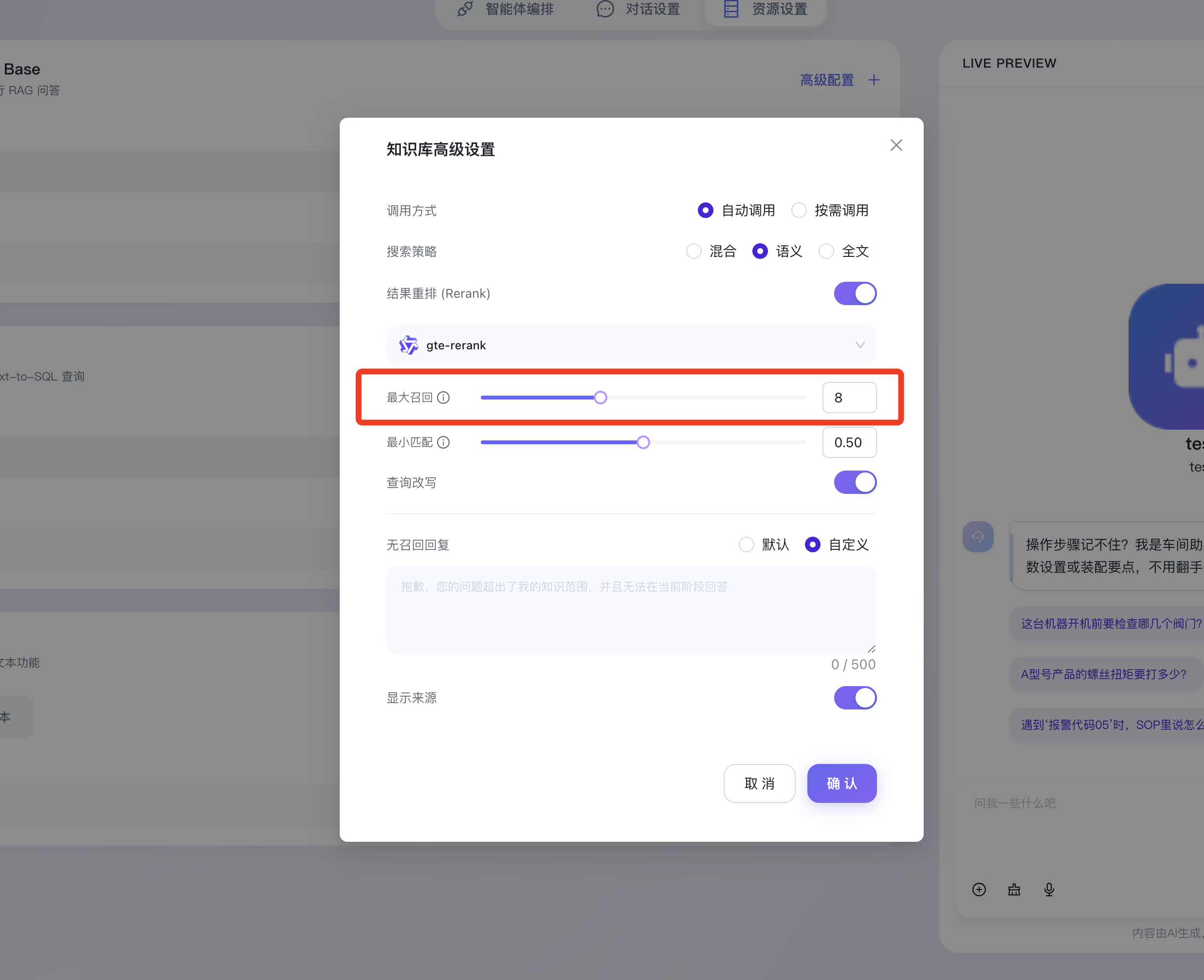
- 最大召回 (Top-K 参数):用于精确设定单次检索中,允许从知识库中提取并打包送给大模型进行阅读参考的最大文档分块(Chunk)数量,适度调整此参数可在保障信息充足的同时,防止 Token 资源消耗过大或引发模型注意力分散。
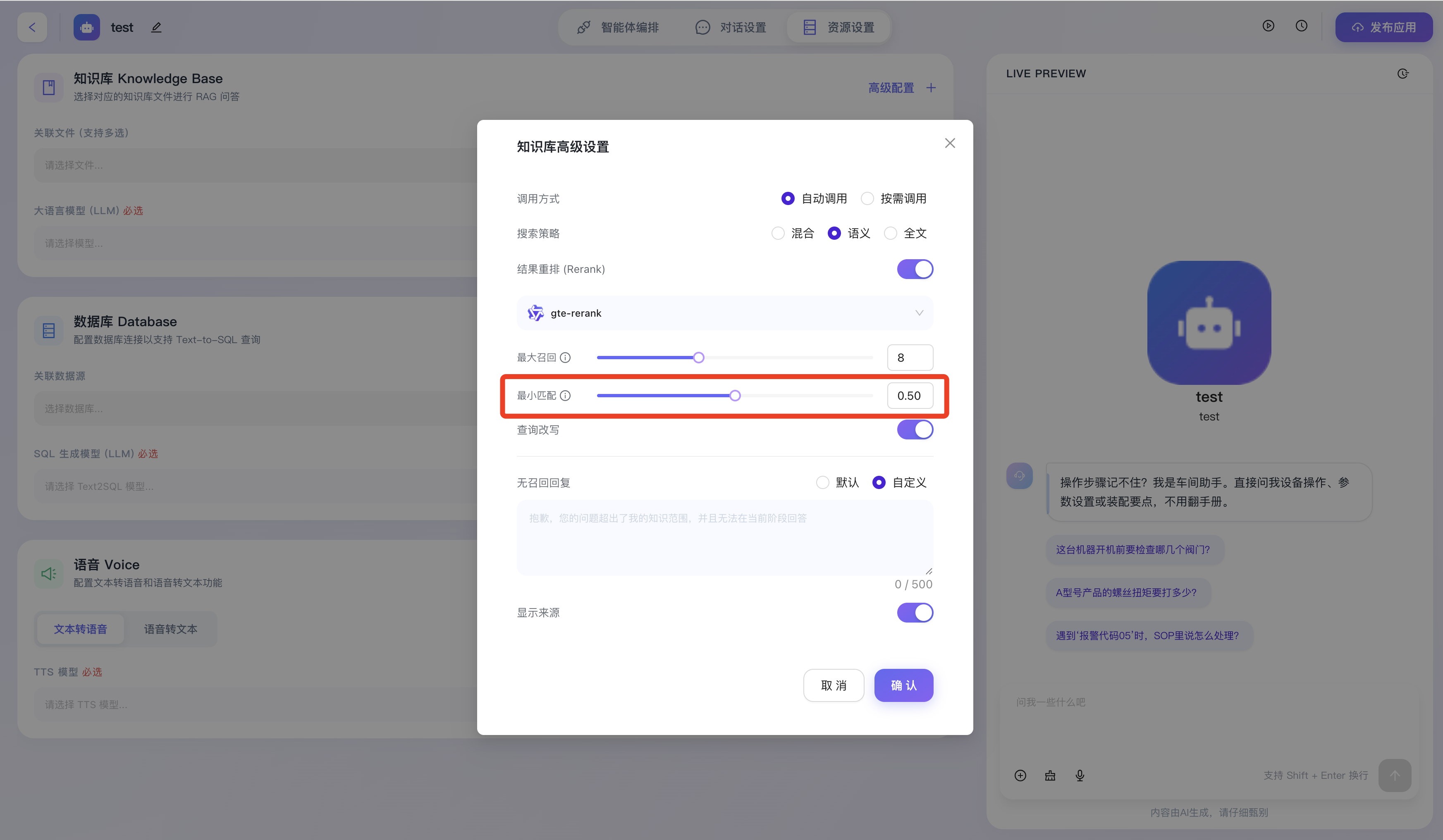
- 最小匹配 (相似度阈值):用于设定召回内容的最低相关性得分门槛。低于该设定的文档切片将被系统判定为“噪音”并直接丢弃,确保输送给大模型的上下文“宁缺毋滥”。
- 查询改写:开启后,系统将在实际发起数据库检索前,自动利用大语言模型对用户的原始提问进行意图补全、关键词扩写或纠错重组,能极大程度缓解因用户输入过于口语化、存在错别字或缺乏上下文导致的检索失败问题。
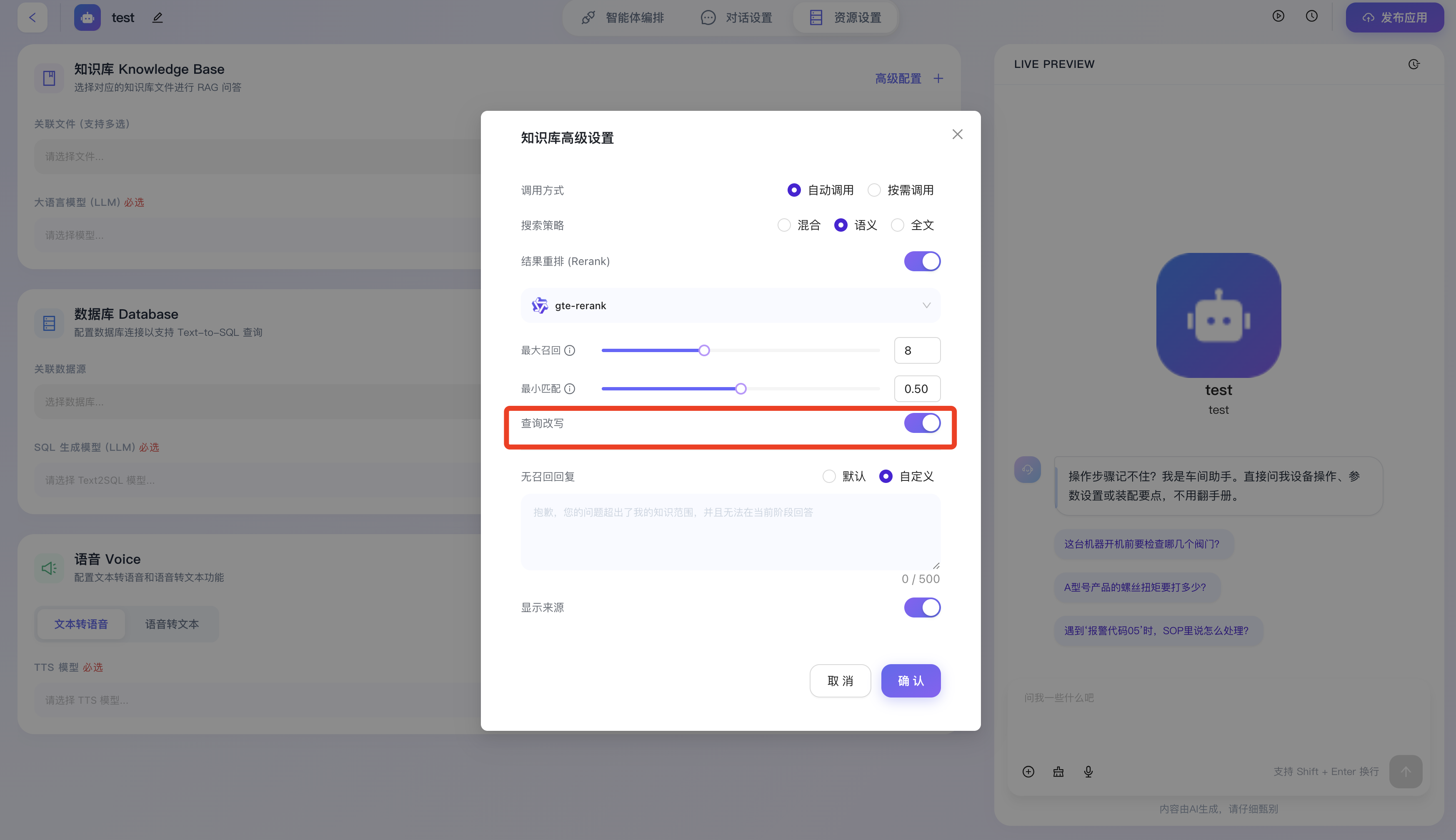
- 无召回回复:用于定义当系统穷尽上述所有检索策略,仍未能从知识库中找到任何与用户问题相关的内容时,智能体的标准回应话术。
- 支持“默认”提示与“自定义”模式。
- 如果选用 自定义 模式,开发者即可在下方的文本框内(支持最多输入 500 个字符)编写专属的兜底声明,此配置可有效切断模型进行无根据“幻觉”推理的路径,保障业务输出的严谨性。
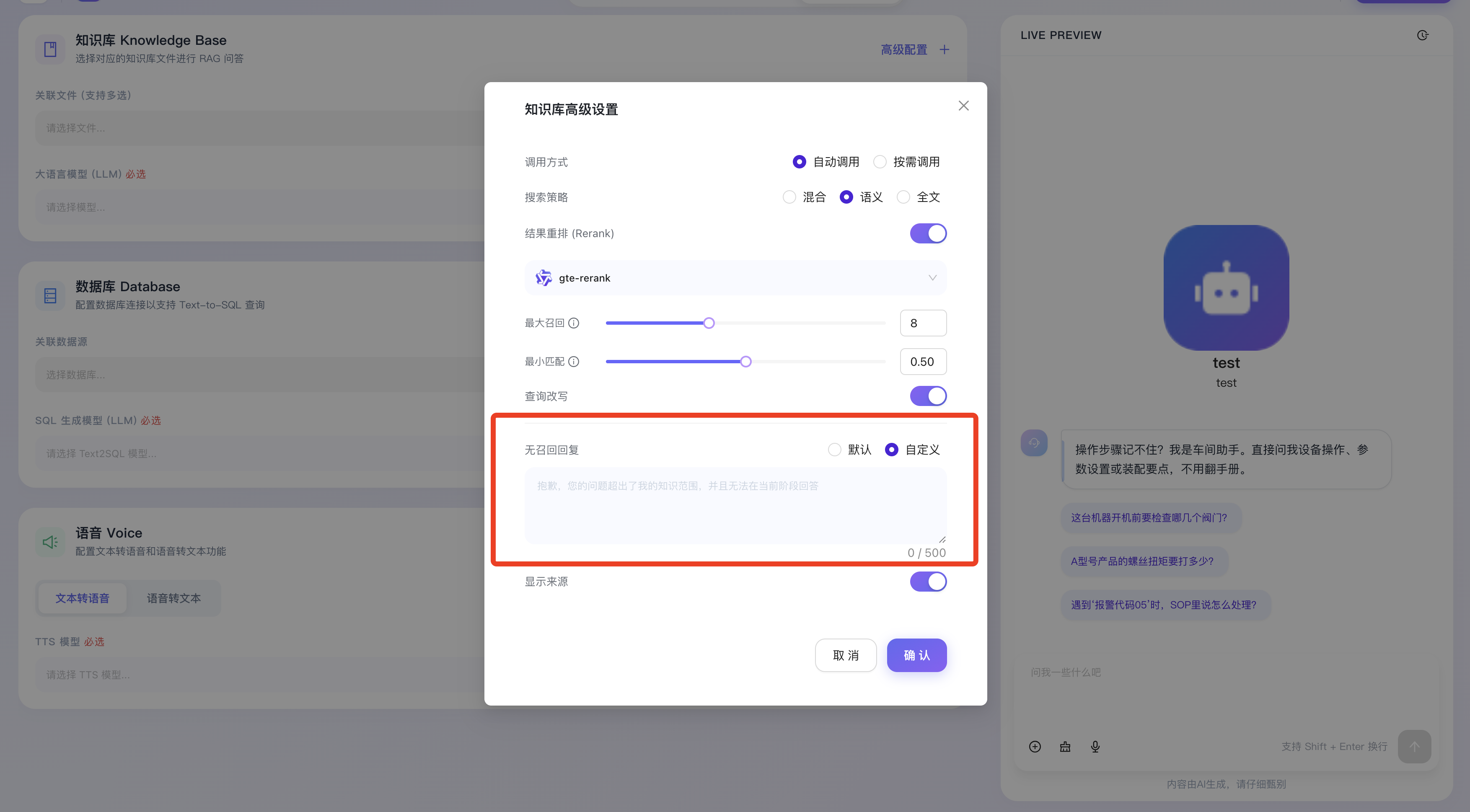
- 显示来源:开启后,智能体在生成基于知识库的自然语言回答时,将在前端交互界面自动附带引用的原文片段或参考文档来源标注。这使得终端用户能够随时点击追溯,大幅增强了 AI 回答的权威性与用户的信任感。
3.2 数据库配置
该部分主要为智能体赋予直接对话业务系统底层数据库的能力,传统的数据库查询高度依赖专业的开发人员编写 SQL 脚本,而通过开启 Text-to-SQL 功能,智能体能够精准理解终端用户的口语化查询意图,并将其自动转化为标准的 SQL 语句去执行底层查询。这极大地降低了数据获取与分析的门槛,使得非技术人员也能通过简单的对话,实时获取精准的业务统计指标或结构化明细数据。
包含的配置功能点如下:
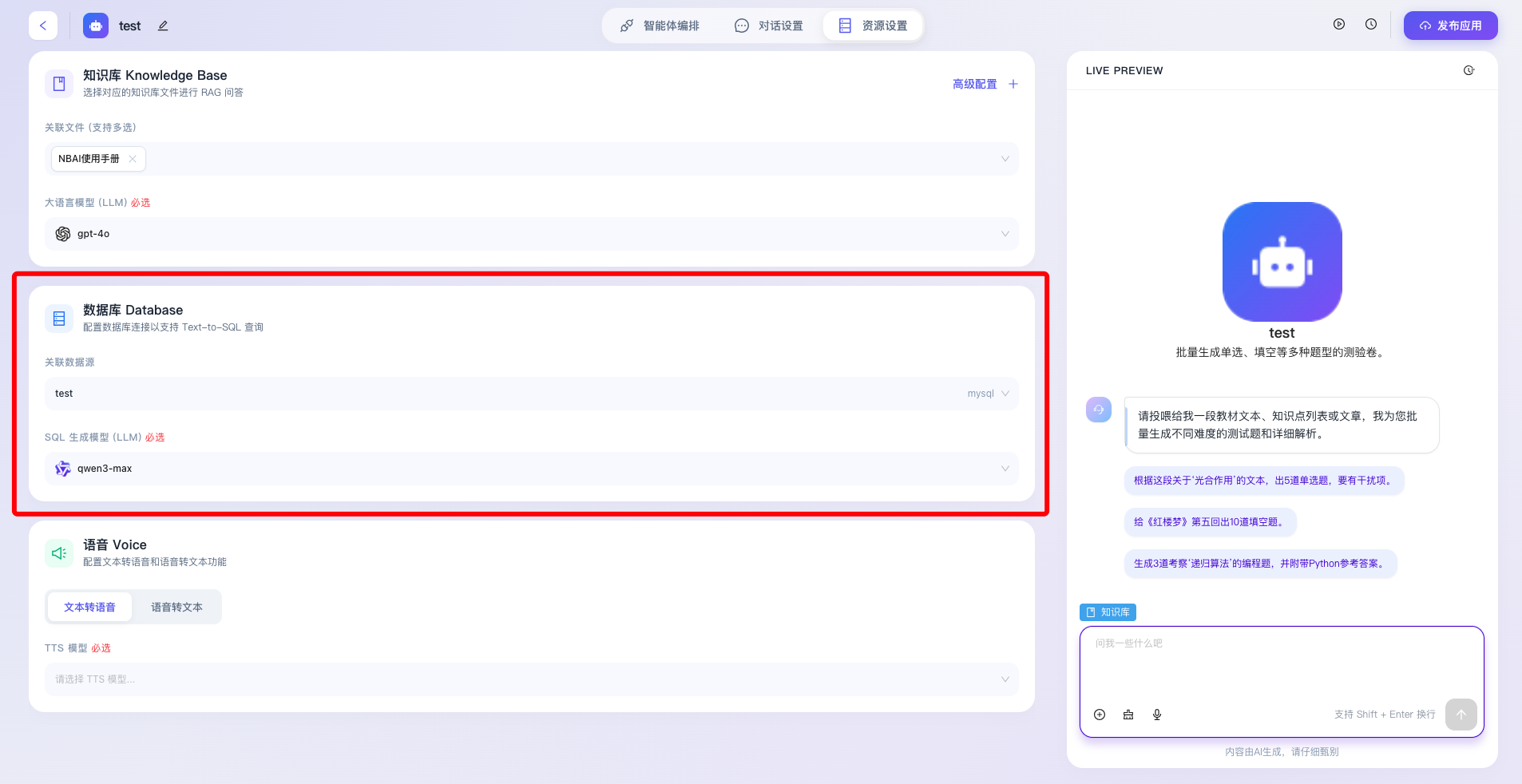
- 关联数据源:提供下拉菜单供开发者选择并绑定平台内已配置完成的结构化数据库实例,通过安全合规的凭证关联,确保智能体仅能在被授权的特定数据域内进行表结构读取与数据查询操作。
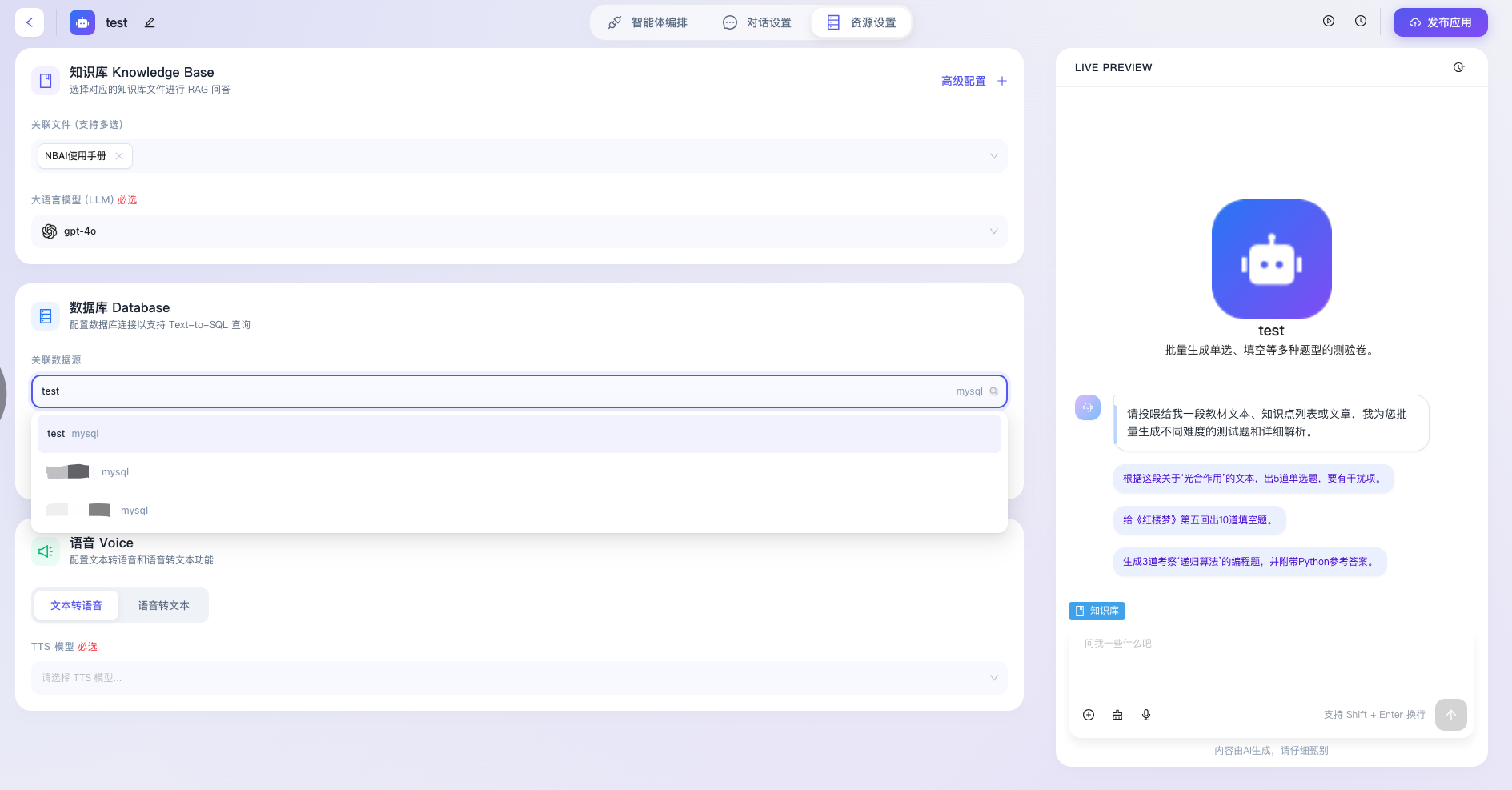
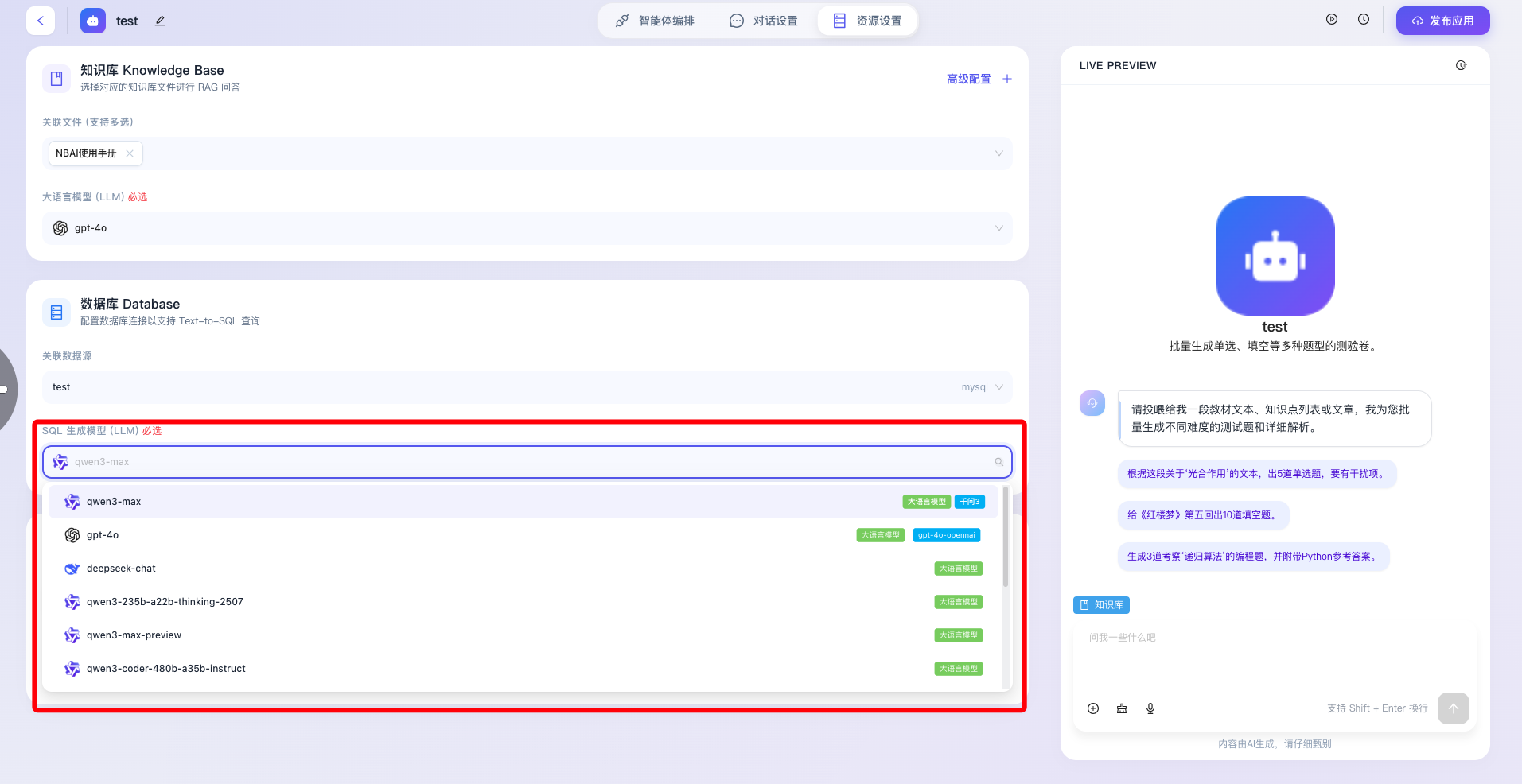
- SQL 生成模型(LLM)必选:专门用于指定负责“自然语言转 SQL 代码”这一复杂编译任务的大模型(如图中选中的 qwen3-max)。由于代码生成对模型的逻辑严谨性、数据库方言兼容性及语法准确度要求极高,系统将其设为必填项,以保障数据查询指令能被正确编译并安全执行。
3.3 语音交互配置
该部分专注于拓展智能体的多模态交互边界,实现从单一的“文本打字对话”向“声文并茂”的立体交互形态升级。在车载助手、智能客服硬件、适老化应用或双手被占用的特定工业业务场景中,语音能力的接入显得尤为关键。通过集成先进的语音合成与识别算法,开发者可以赋予智能体“听懂”人类语言并用拟人化声音进行“解答”的能力,从而显著提升终端用户的沉浸感、操作便捷度以及情感共鸣。
包含的配置功能点如下:
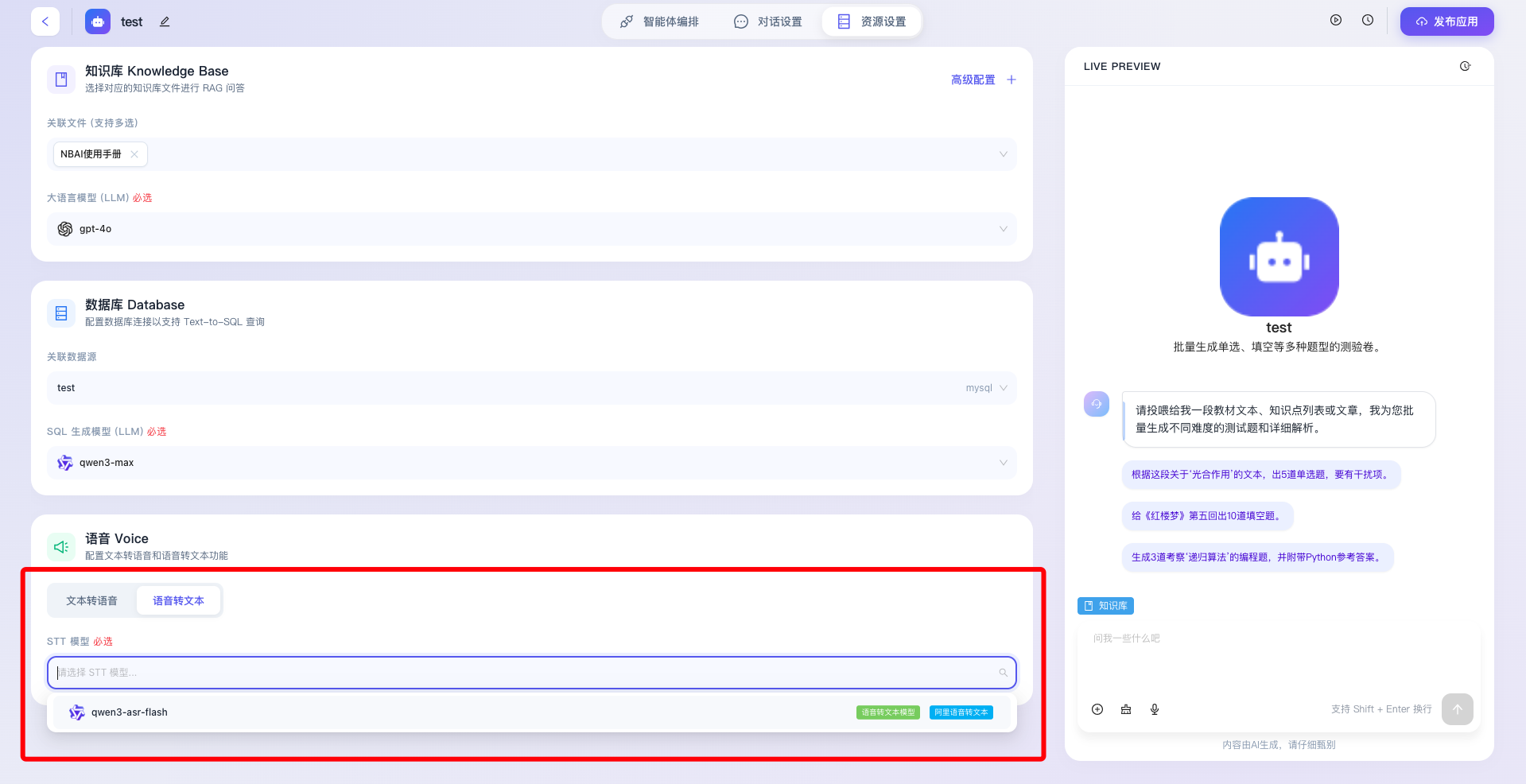
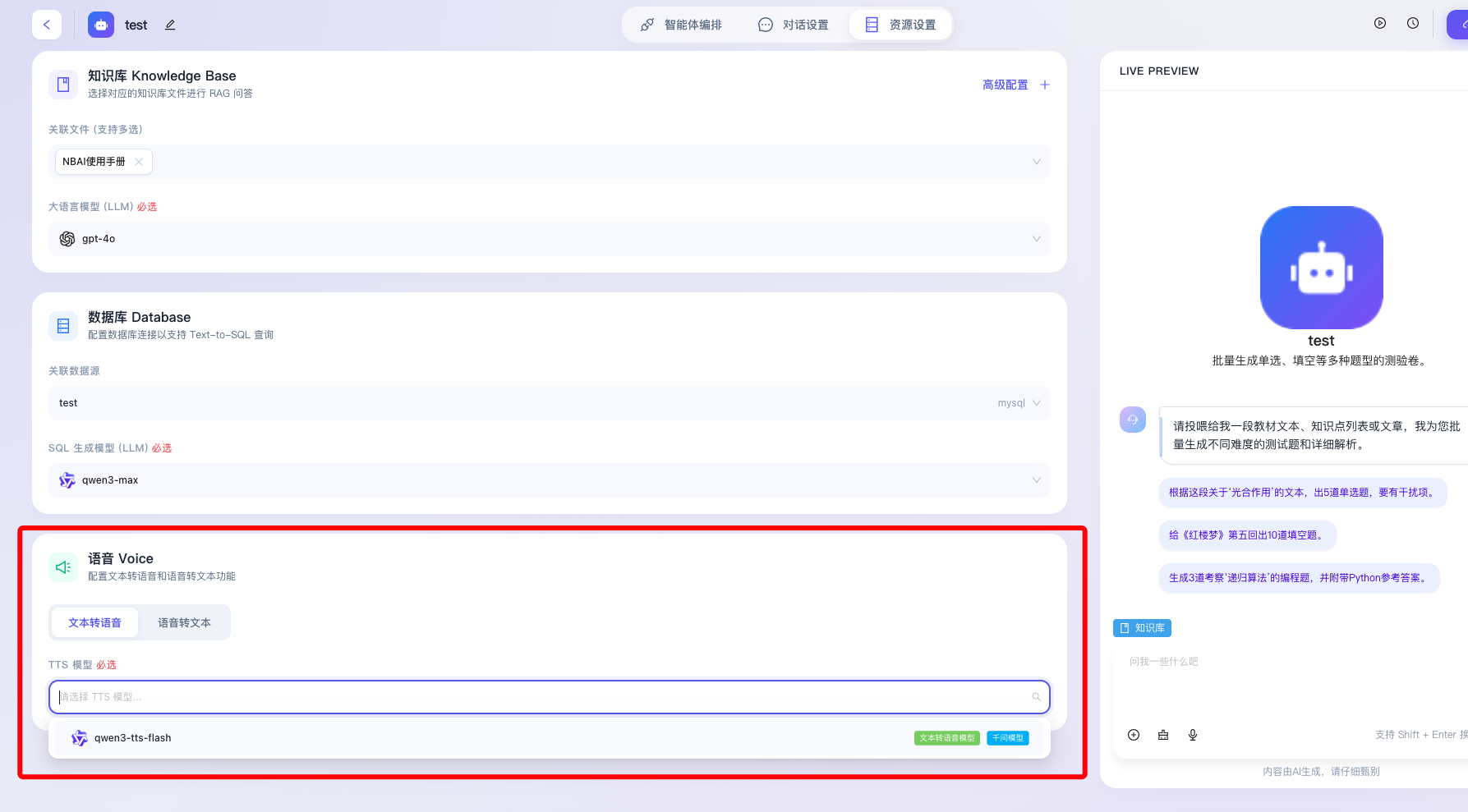
- 双向交互链路切换:界面提供清晰的 Tab 按钮组件,允许开发者分别对 文本转语音(TTS, Text-to-Speech) 即“让机器发声”,以及 语音转文本(STT, Speech-to-Text) 即“让机器听写”两种截然不同的音频处理链路进行独立设置。
- TTS 模型(必选):在选中“文本转语音”激活状态下,系统要求开发者必须指定一个底层的声音合成模型。通过展开“请选择 TTS 模型”下拉菜单,开发者可以根据应用的人设定位,选择不同性别、音色、语调或具备特定方言特色的声学模型,确保输出的语音流完美贴合实际业务场景的调性。