快速配置企业的专有知识库
为了适应不同数字化成熟度的企业环境,NebulaAI 提供了极具弹性的“双模驱动”知识库解决方案。无论您是否已经拥有独立的数据管理系统,NebulaAI 都能无缝融入您的技术栈,打通数据孤岛,让智能体从“通用与闲聊”进化为“专业与执行”。
本案例将详细拆解以下两种最典型的接入场景,助您快速落地:
1. 接入自有知识库
1、适用于:大型企业、已有成熟文档管理系统、极高数据隐私要求、已有知识库/CMS系统的企业。
许多数字化程度较高的企业,内部已经部署了如 Elasticsearch、Wiki、Confluence 或自研的向量数据库系统,沉淀了海量的高质量业务文档,在这种模式下,可以利用NebulaAI的插件机制,实时请求外部系统获取相关片段,NebulaAI 负责对返回的信息进行推理、整合与生成回复,这样的好处:
- 数据主权: 原始数据不出域,严格保障信息安全。
- 架构解耦: 避免数据迁移带来的繁重工作,保护既有 IT 资产。
- 实时同步: 外部系统的更新即刻反映在智能体的回答中。
本次将演示通过内部的知识库API调用,在NebulaAI中可以如何配置和使用;
1.1 创建插件
在NebulaAI平台中,点击左侧的【插件】功能,选择创建插件;
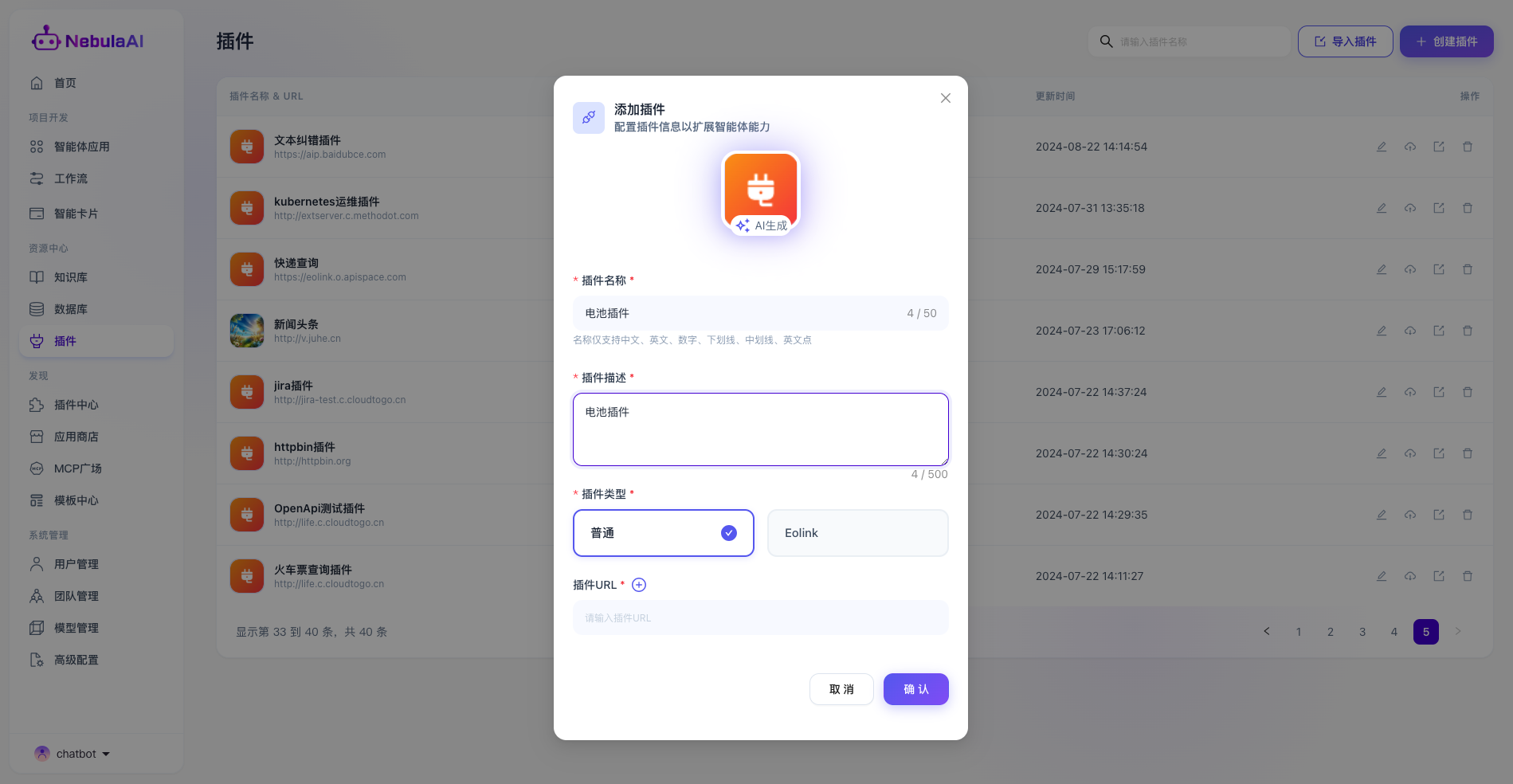
填写插件的名称、插件描述、插件类型和对应的Url地址
1.2 创建工具
创建了插件后,可以在插件中,进行工具的创建
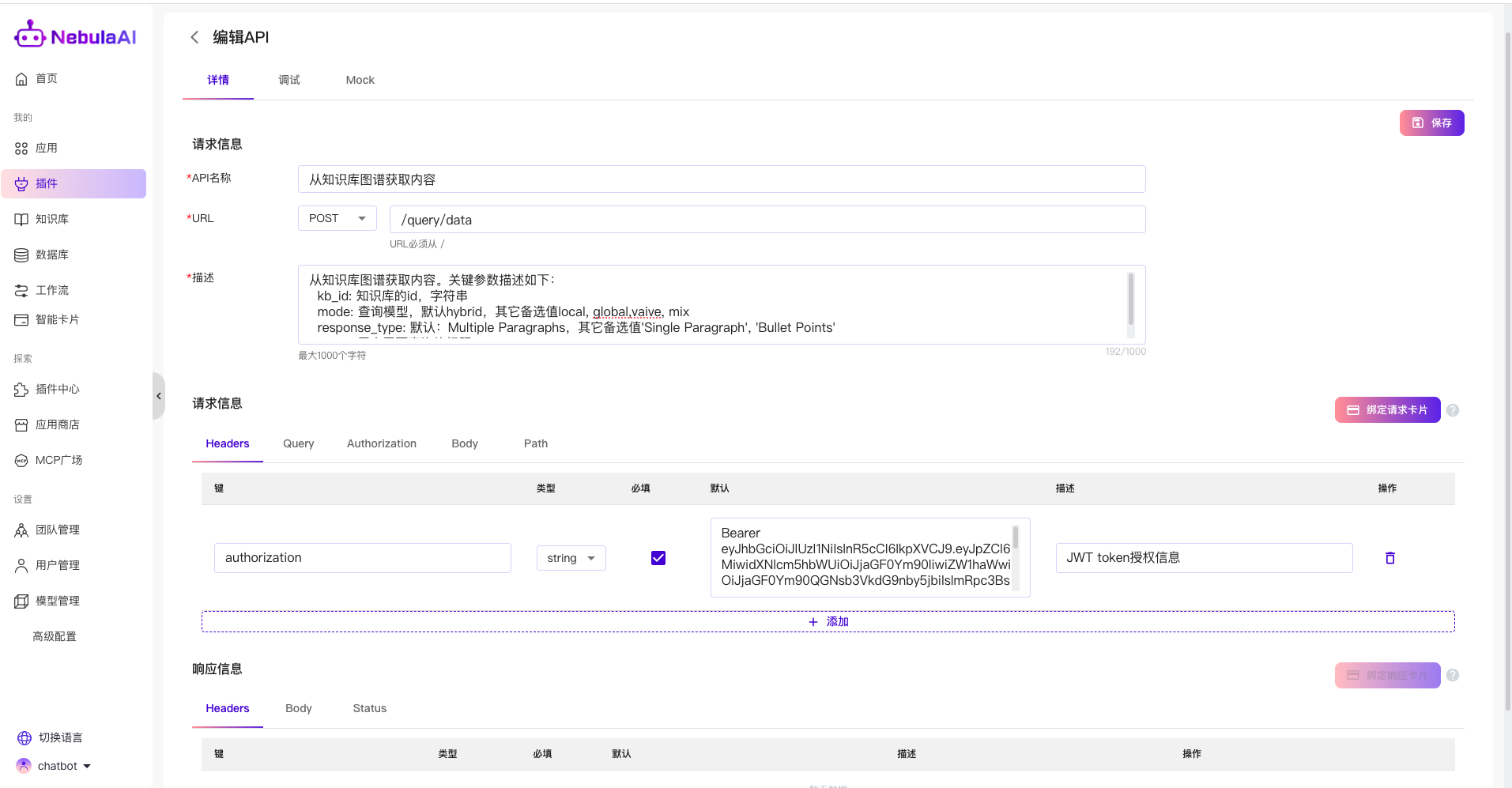
可以填写对应API的内容
1、API名称:定义这个API的名称,便于智能体识别到对应的api;
2、URL:这个接口的请求方法和PATH
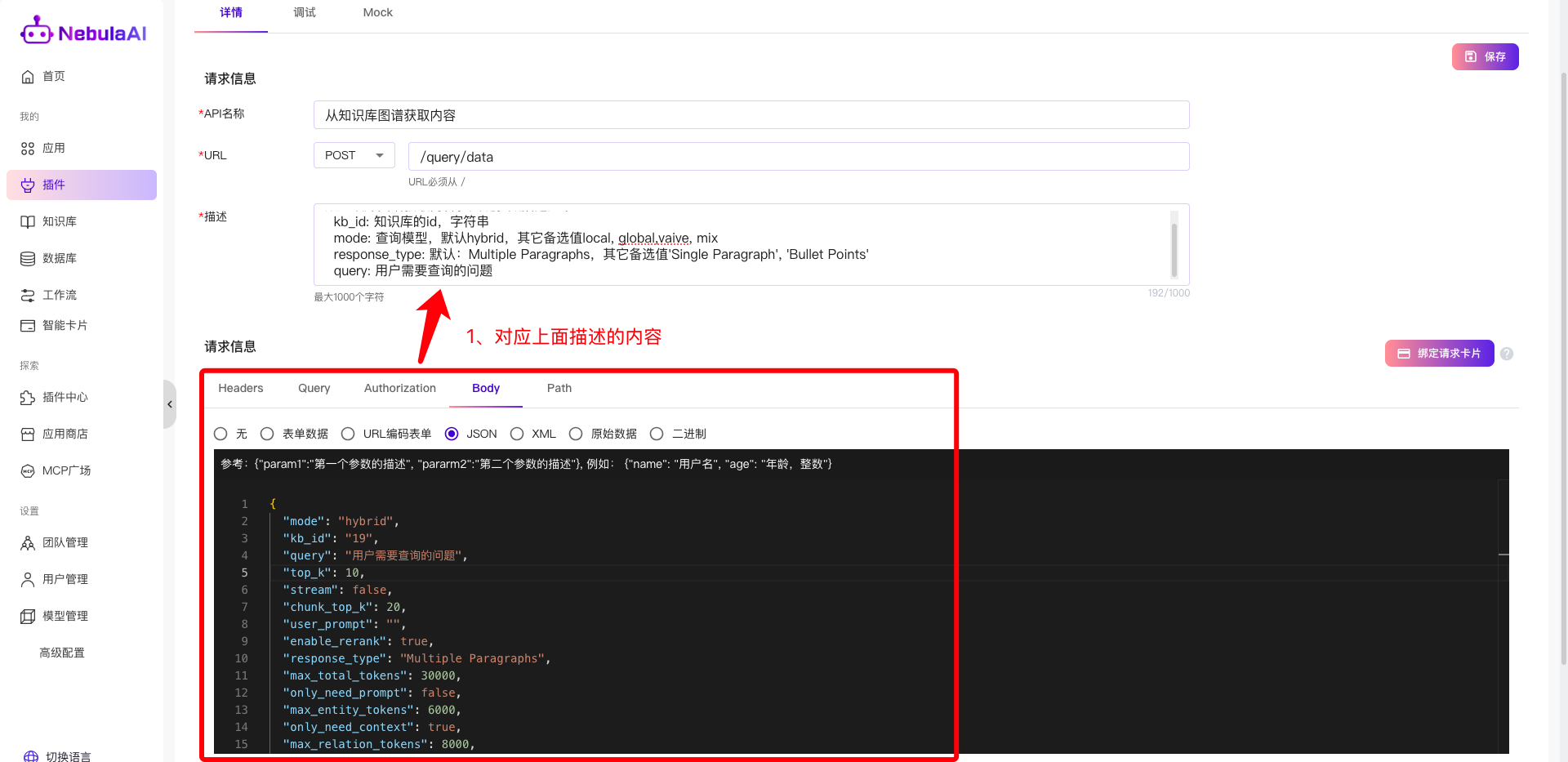
3、描述:可以填写一些内容,使得智能体更加精准理解,例如参数字段描述等;
4、请求信息:配置该接口对应的一些请求参数,例如鉴权信息等
例如:Headers的配置
例如:Body的配置,在描述中让智能体更精准理解
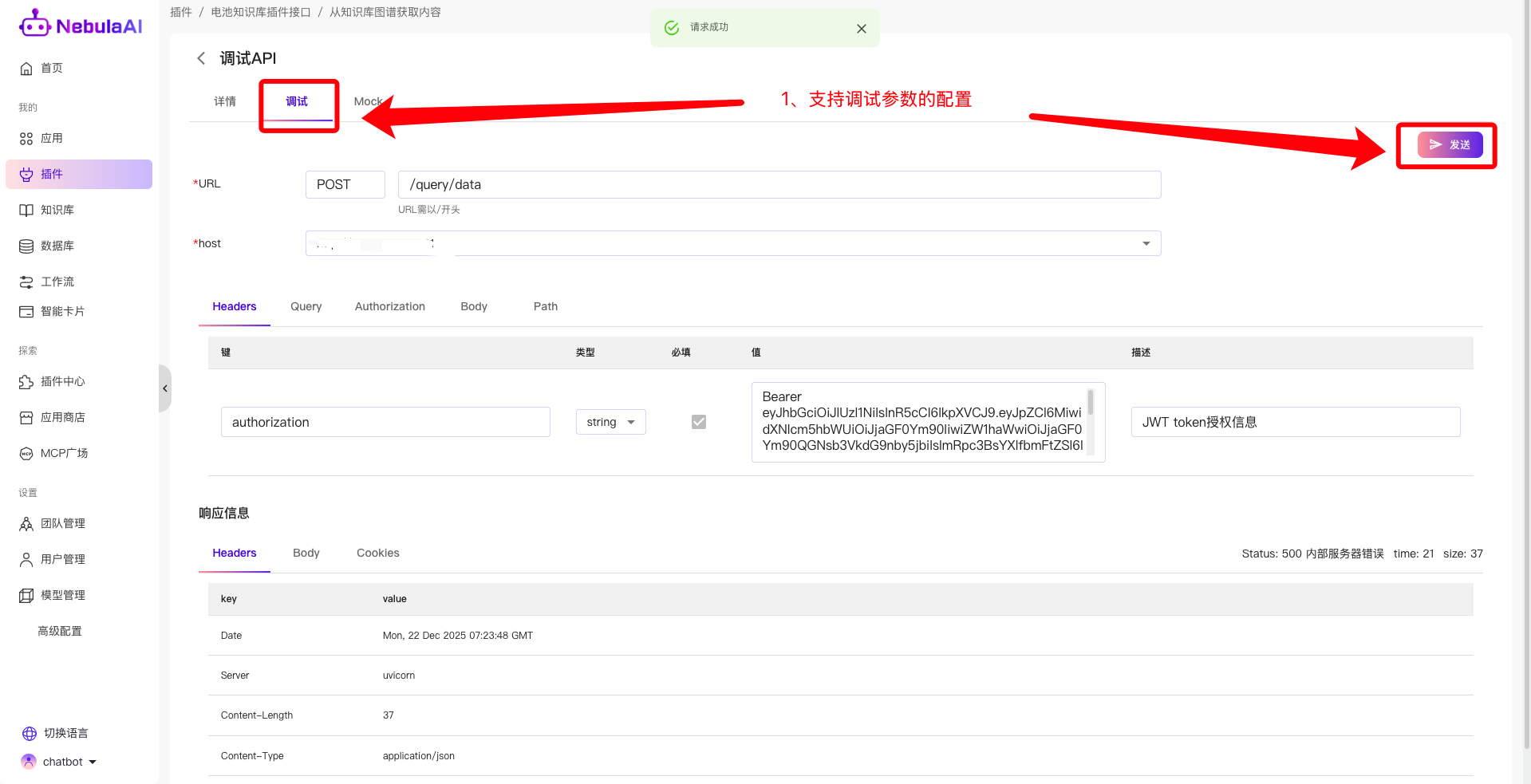
配置完后,可以点击调试,测试下参数的配置
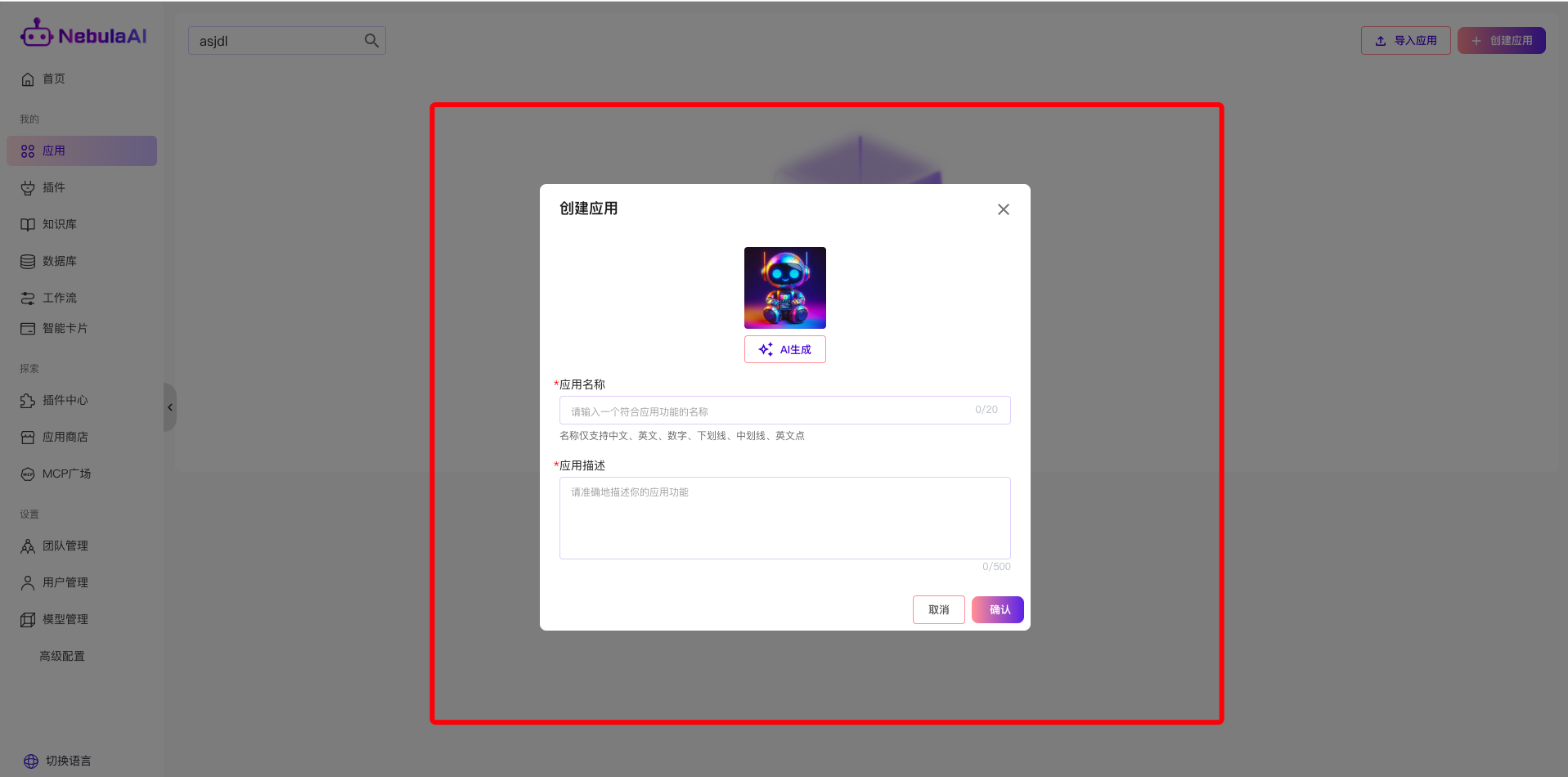
1.3 创建智能体应用
在NebulaAI平台中,点击左侧的【应用】功能,创建智能体应用;

填写应用的名称和应用描述,便于后续找到对应的智能体应用
1.4 智能体应用配置
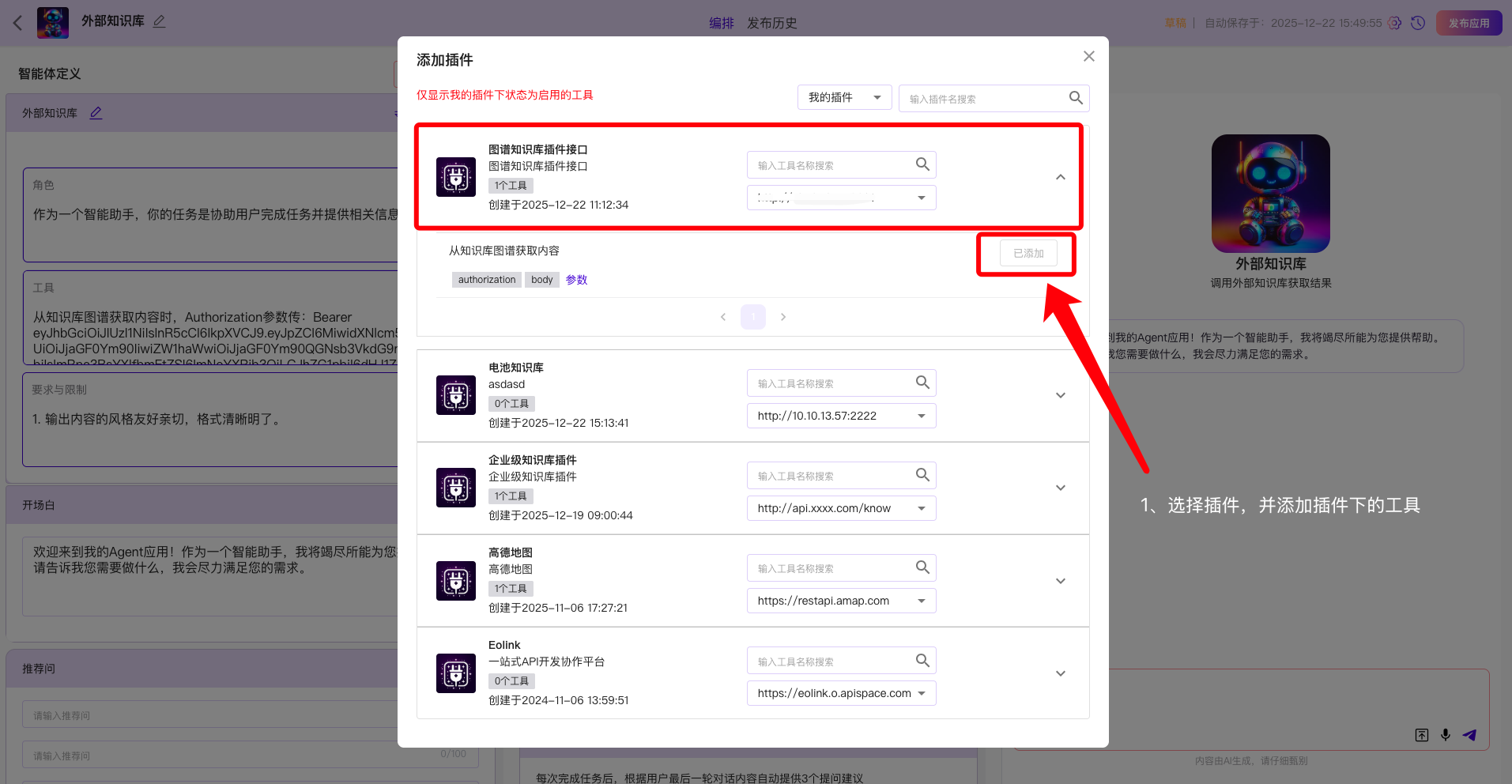
点击智能体中的插件添加按钮,为智能体添加插件
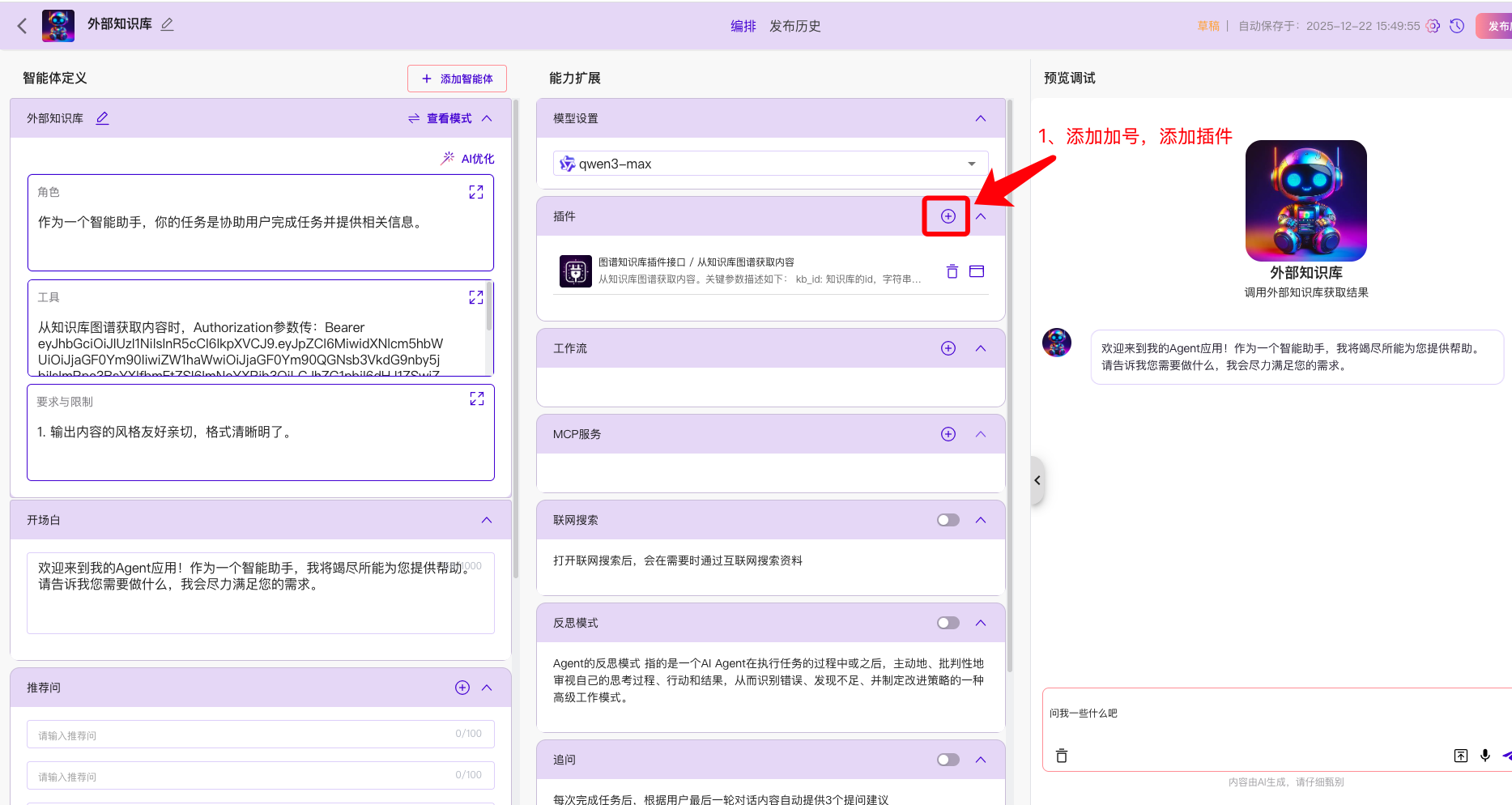
选择对应要添加的插件(例如,本次示例添加的是图谱知识插件接口),添加了一个工具,名叫:从知识图谱获取内容
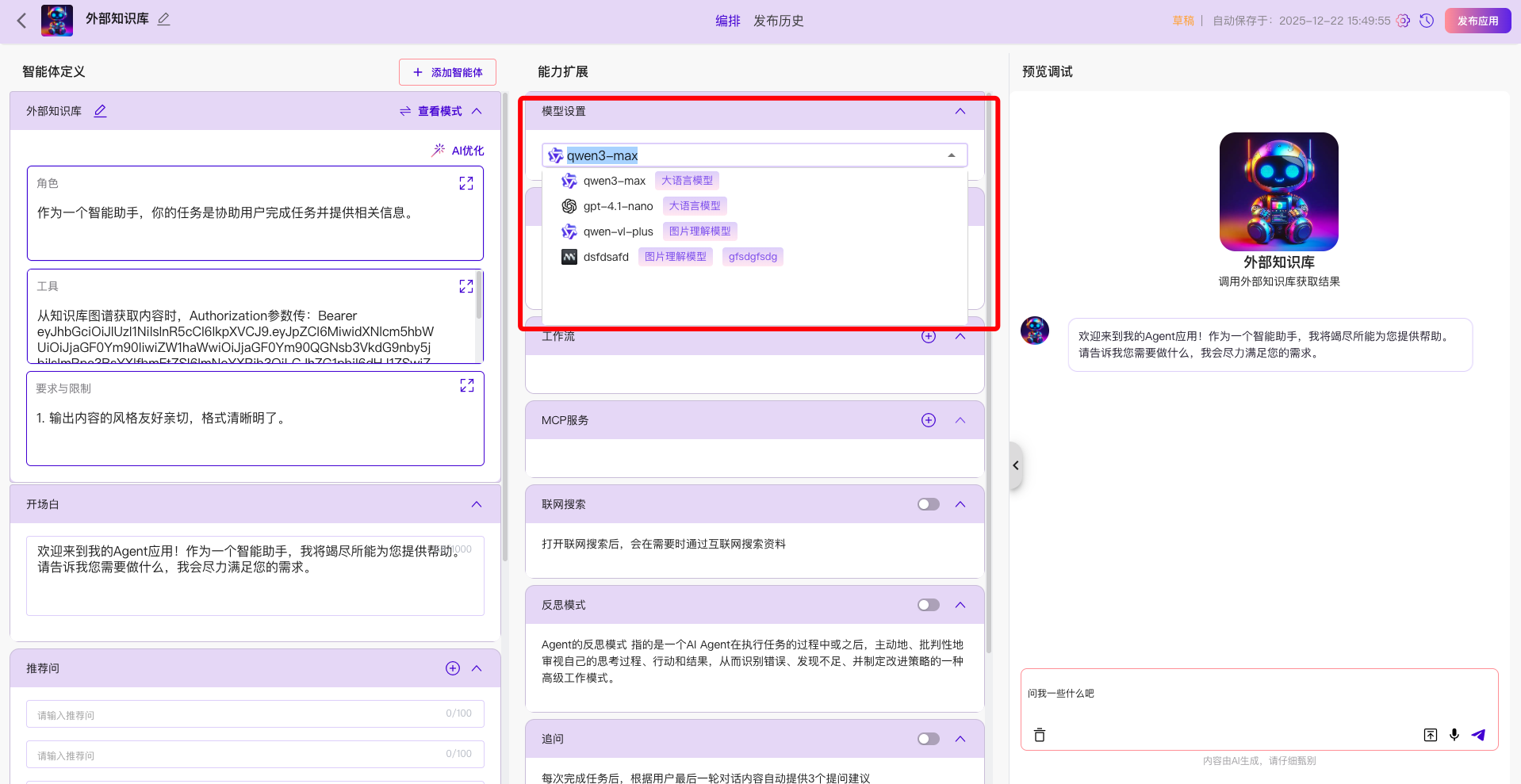
选择对应配置的大模型,例如本次选择的是qwen3-max
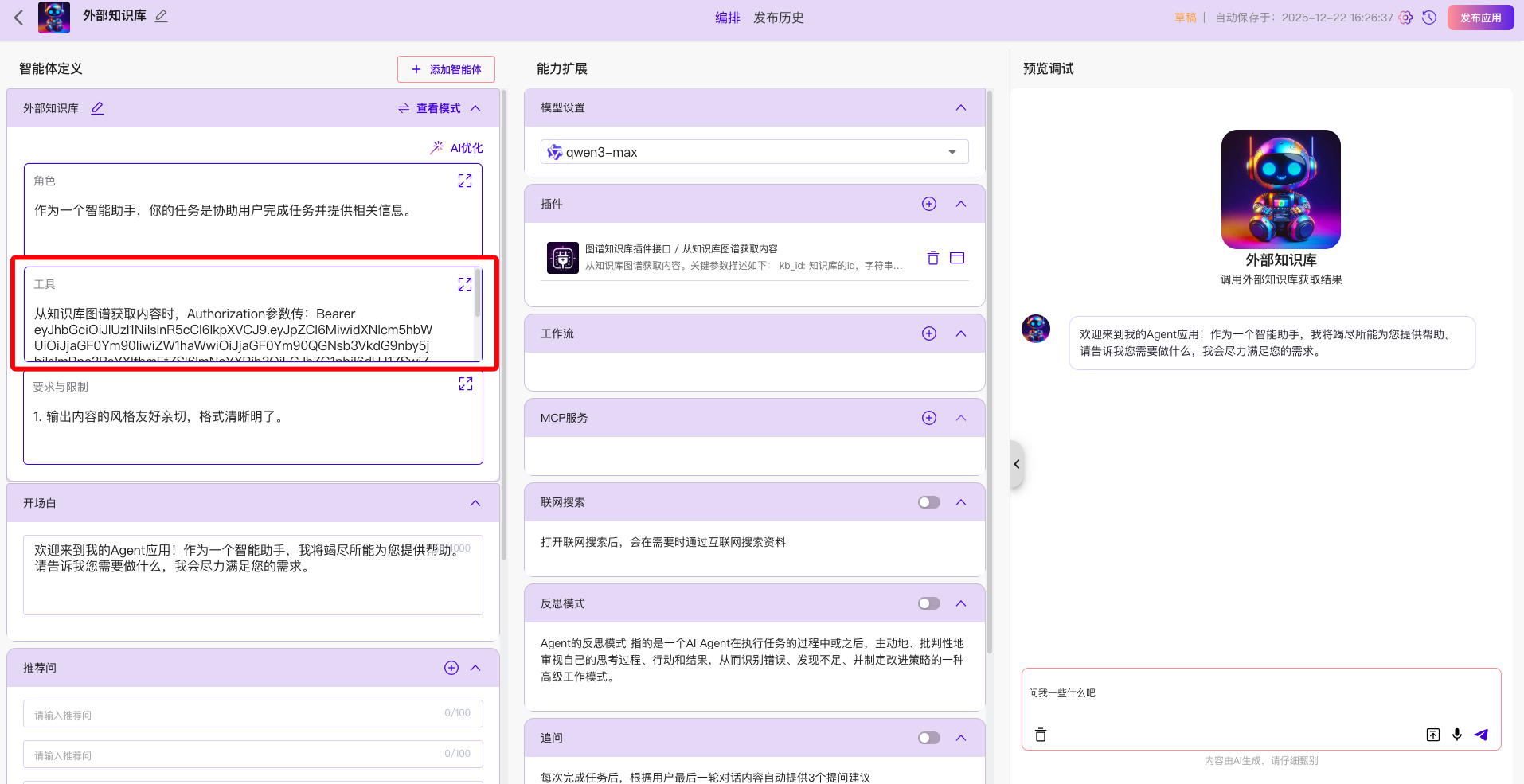
搭配智能体的能力定义,例如,调用知识库时,需要鉴权信息,在工具栏里面,配置一个鉴权参数:
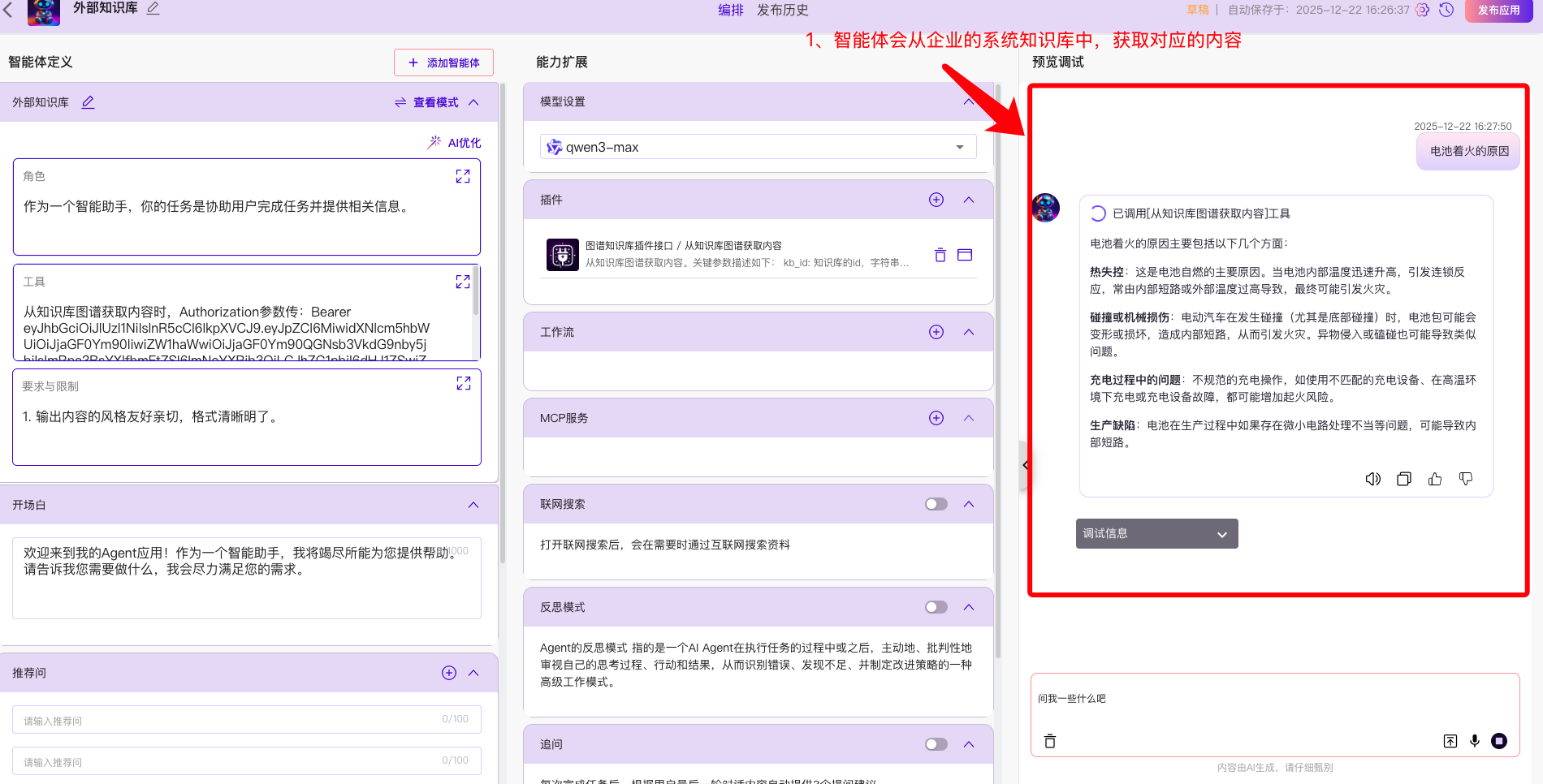
1.5 对话测试
配置完上面的内容后,一个知识库智能体就配置完成了
1.6 应用发布
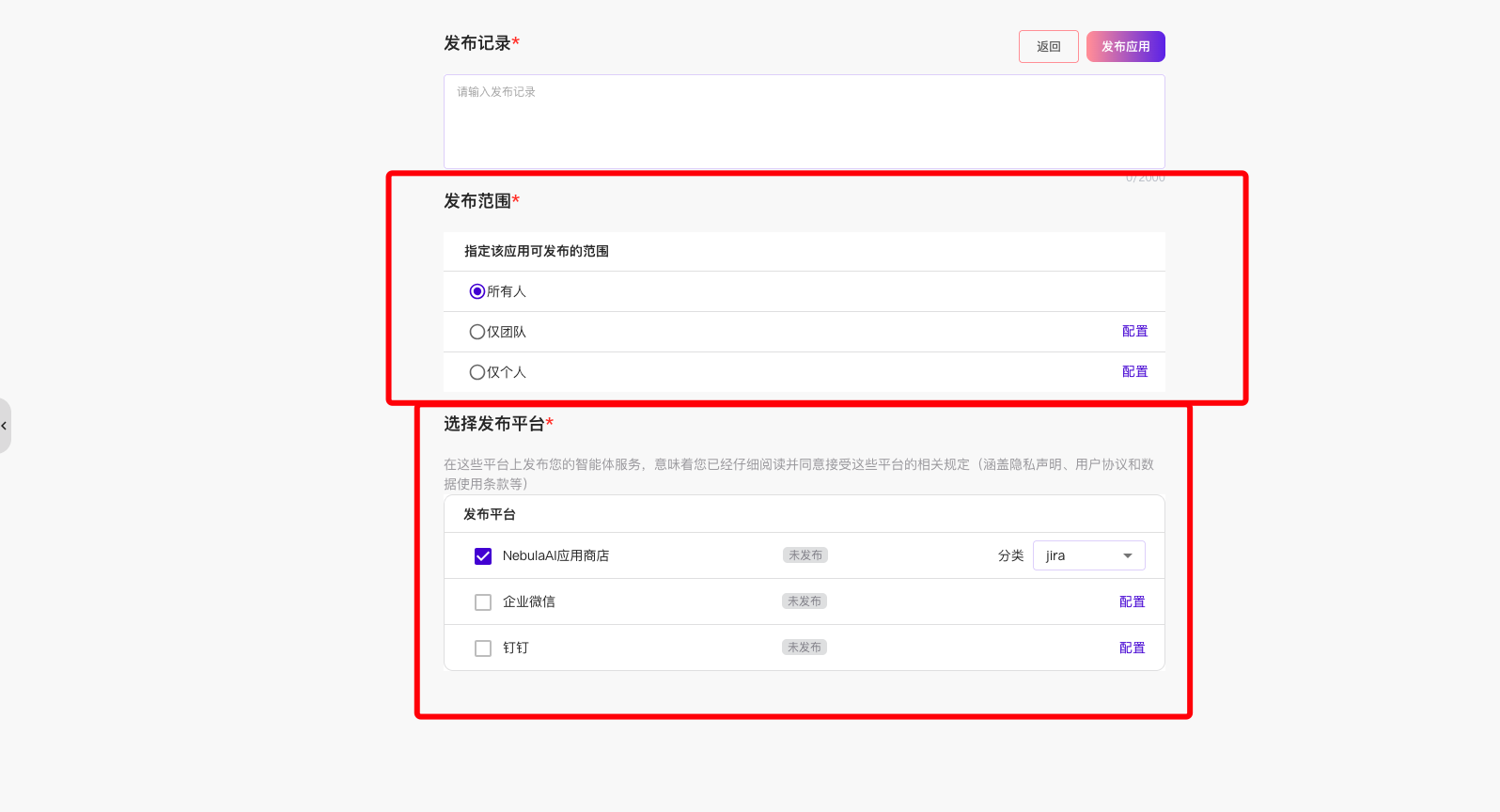
点击右上角的应用发布,可以进行发布的渠道和权限配置;
可以设置本次的纪录内容、发布范围(权限配置,可以设置哪些团队或个人可以使用)、发布平台(可以发布到第三方的渠道如企业微信、钉钉、微信等及内部的应用商店)
2. 使用NebulaAI全链路内置 RAG 引擎
1、适用于中小企业、创新业务部门,针对尚未建立知识库的企业/项目。
对于新兴业务线或尚未搭建复杂数据中台的团队,面临着大量的 PDF、Word、Markdown 离散文档,急需一个开箱即用的能力来管理知识并赋能 AI,这时候NebulaAI的原生知识库能力,自动调用内置的高性能 Embedding 模型将非结构化数据转化为向量,并存储在 NebulaAI 托管的向量数据库中,用户在提问时,系统自动完成语义检索与匹配,确保知识的精准和准确性:
- 冷启动快: 零代码操作,上传文档即可用,5分钟构建领域专家。
- 自动调优: 内置最佳实践的分片策略与混合检索算法,无需专业的算法工程师调参。
- 可视化管理: 提供直观的知识库管理后台,方便运营人员随时增删改查。