基础知识库
在企业级 AI 应用中,通用大模型往往缺乏对特定领域知识、企业内部数据及实时业务信息的理解。
“知识库”是NebulaAI智能体平台中实现检索增强生成(RAG, Retrieval-Augmented Generation)的核心底层基础设施,该模块可以突破大语言模型(LLM)的固有知识截断与上下文长度限制,开发者可以通过创建知识分类库,将企业私域数据(包括文档、网页网页、音视频等复杂格式)转化为模型可检索、可理解的向量数据,赋予智能体专属于特定业务场景的“专家级记忆”,降低模型产生“幻觉”的概率,确保对话输出的精准性与可靠性。
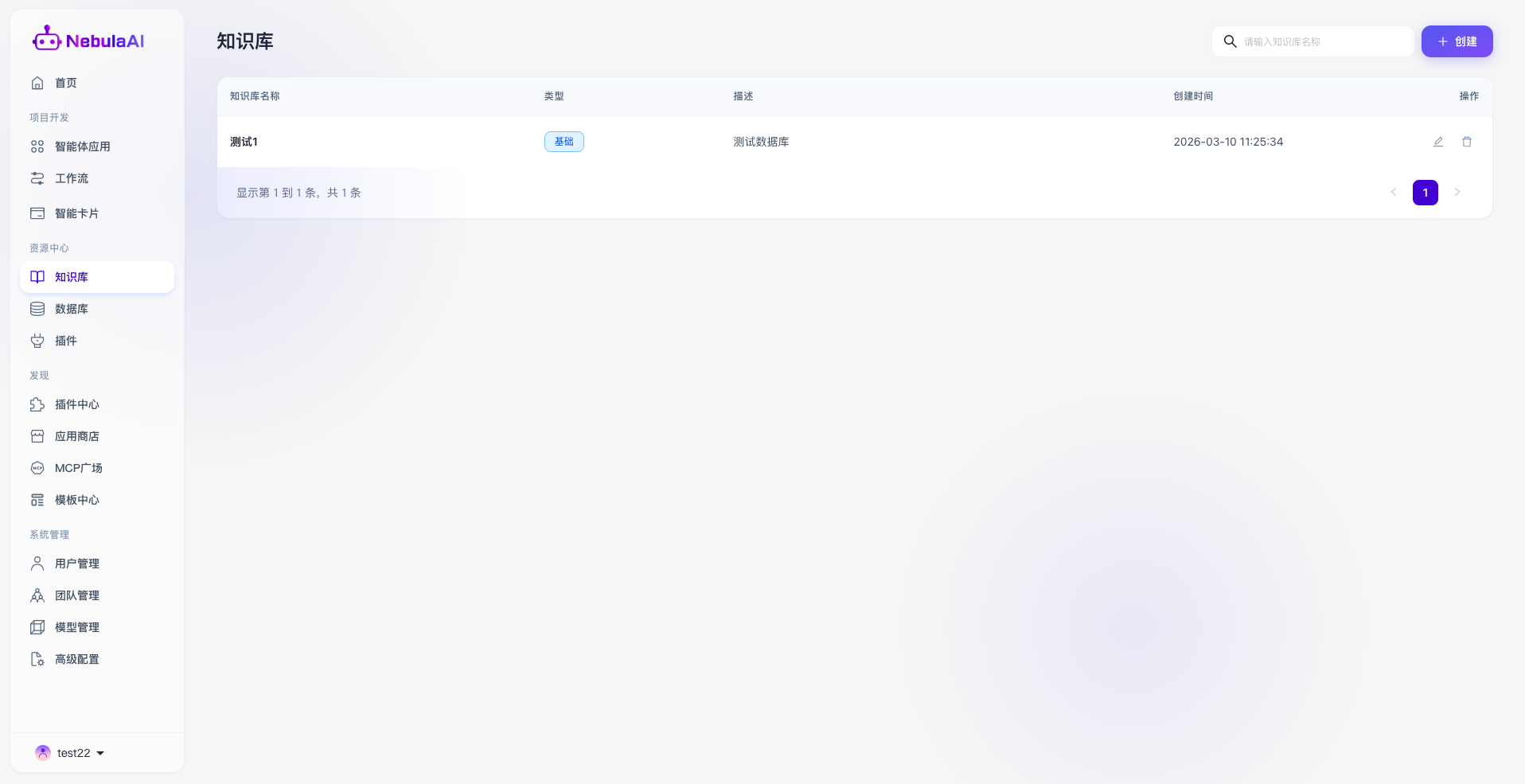
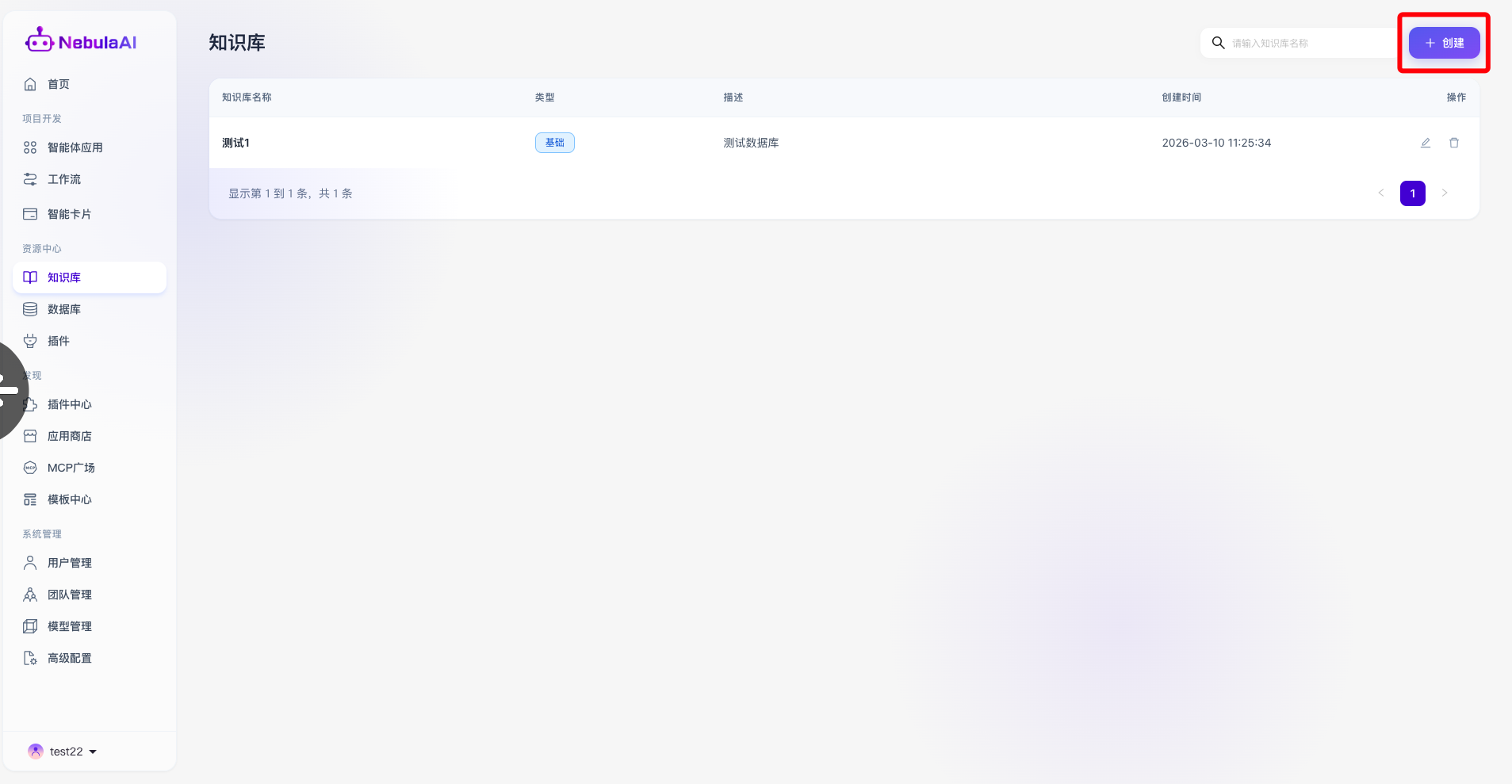
1. 知识库列表
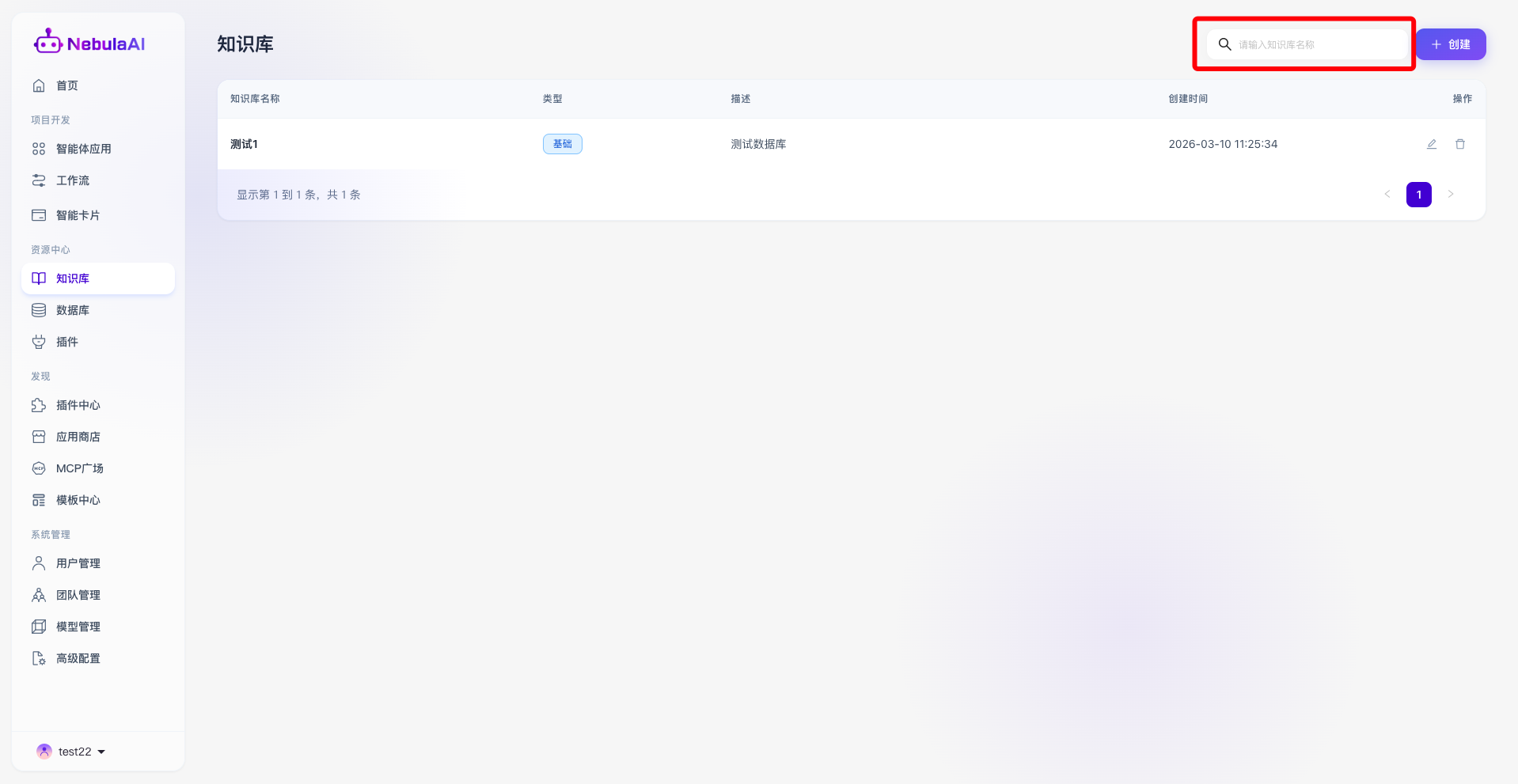
- 模糊搜索:支持通过输入知识库名称进行模糊或精确检索,帮助用户在列表中快速定位知识库。
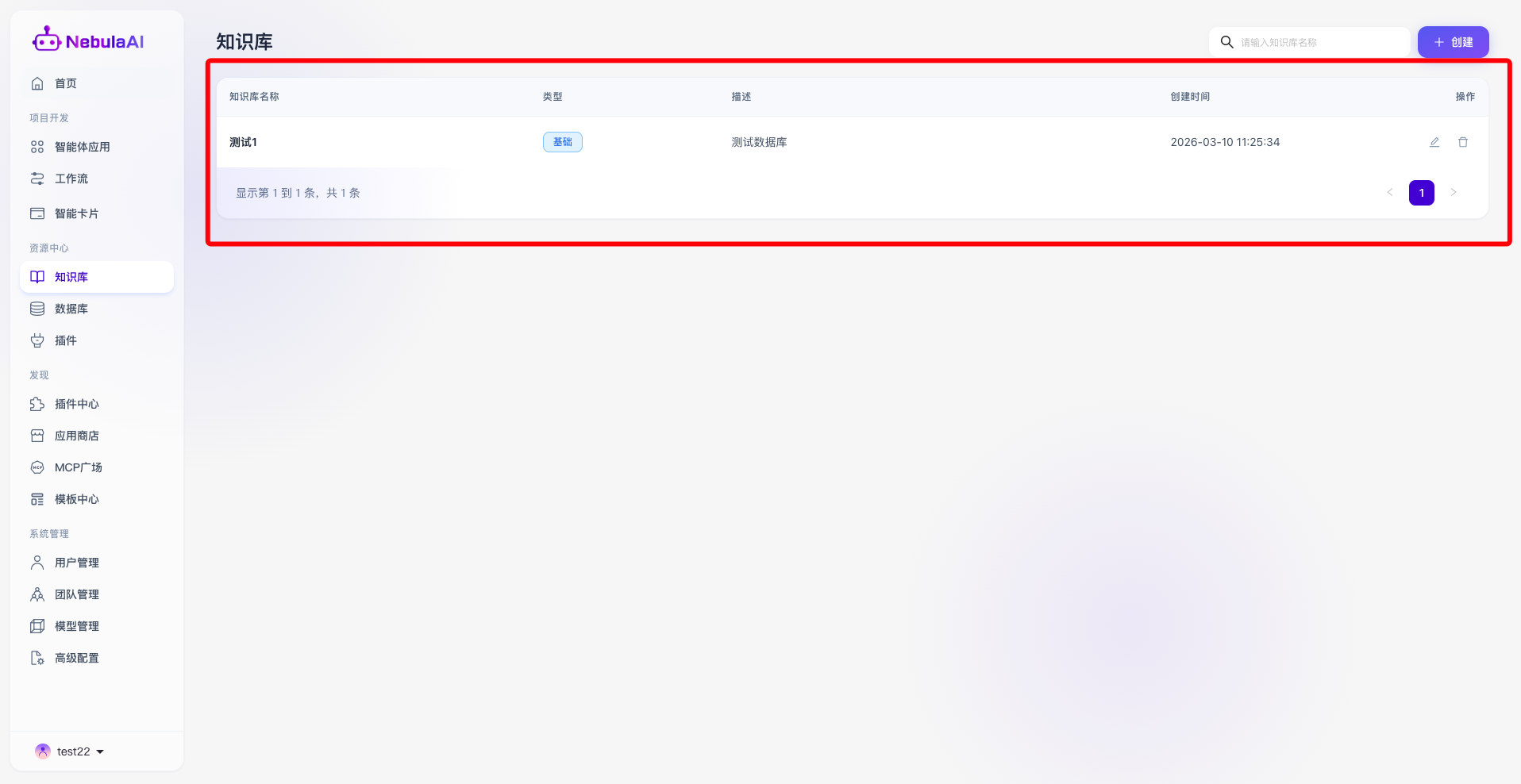
- 列表展示:提供列表方式呈现所有知识库的内容数据,包括:
- 知识库名称: 直观展示库的主题(如:测试1)以及数据组织架构(如标为“基础”类知识库)。
- 类型:可以查看当前知识库的类型,目前有基础/图谱两种知识库内容。
- 描述: 简要描述知识库所涉及的内容,以便于智能体查找。
- 创建时间: 显示当前知识库所创建的时间,便于溯源管理。
- 快捷操作区:提供高频的快捷管理动作,包括“编辑(铅笔图标)”用于更新基础信息,以及“删除(垃圾桶图标)”用于销毁废弃的知识库。
- 知识库创建:右上角提供全局创建按钮,一键开启全新知识域的构建流程。
2. 知识库内容配置页面
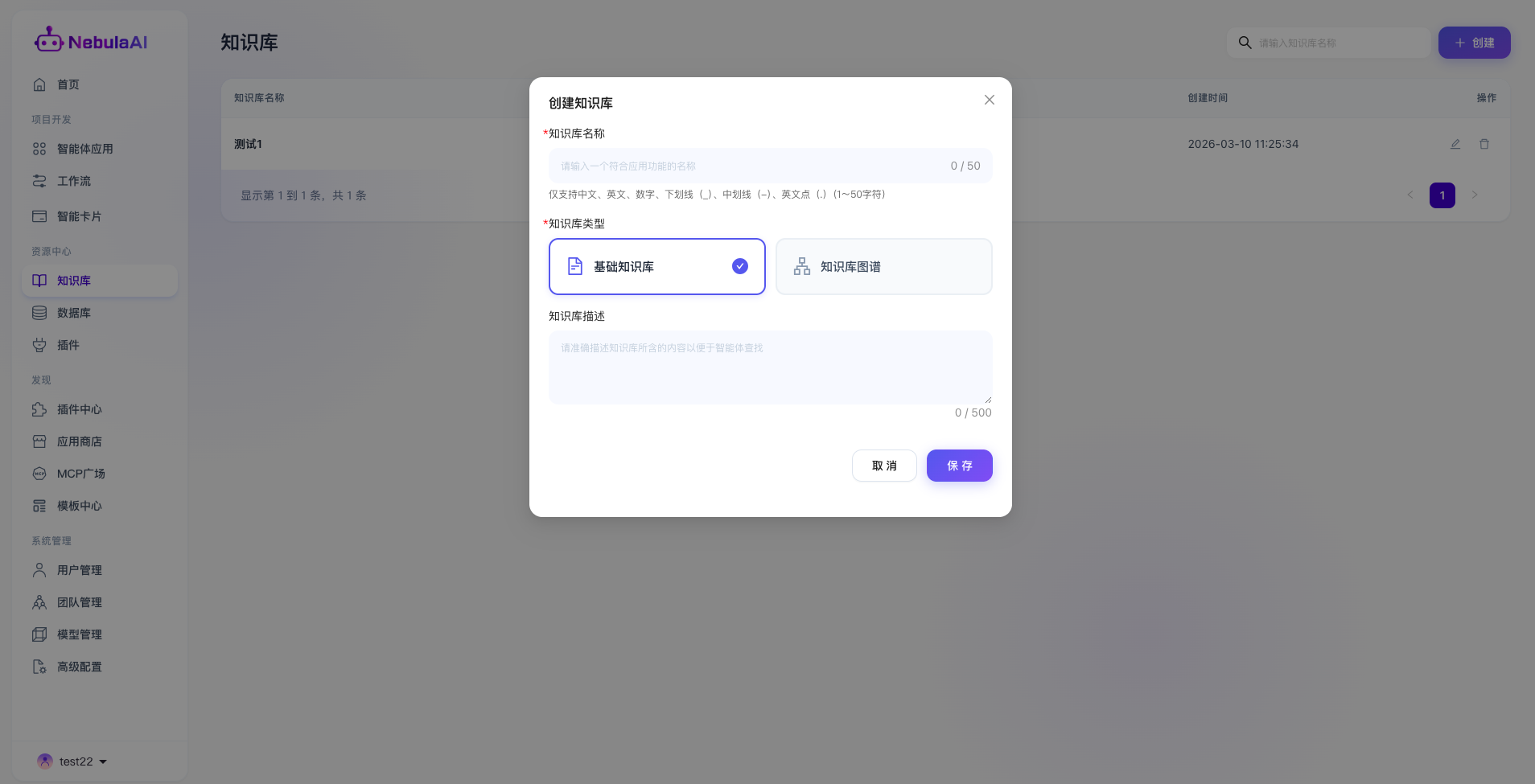
2.1 知识库内容配置列表
点击进入任意指定的知识库后,即进入该知识库专属的“内容配置工作台”,该板块内容呈现的是细粒度的知识切片功能与文件管理。
- 列表展示:提供列表方式呈现该知识库下所使用的文件信息内容
- 知识库名称:展示当前已上传的文件名称内容;
- 类型:展示当前文件的上传方式,共计文档/URL/音视频三种方式;
- 创建时间:精确记录当前文件上传的时间,确保平台资产的安全可控与版本溯源;
- 文件有效期: 标识该知识的时效状态。系统严格控制检索边界,一旦文件超过有效期判定为失效,底层的检索引擎将自动屏蔽该文件,使其无法被检索到,从而彻底规避智能体输出过期或失效的错误信息。
- 文件状态: 实时监控文件的解析与向量化进度(如:成功、处理中、失败等)。
- 操作(功能按钮): 提供全生命周期管理闭环,包含查看(预览分段详情)、编辑(修改配置)、重新上传/同步(保持知识更新)以及删除(物理销毁)功能。
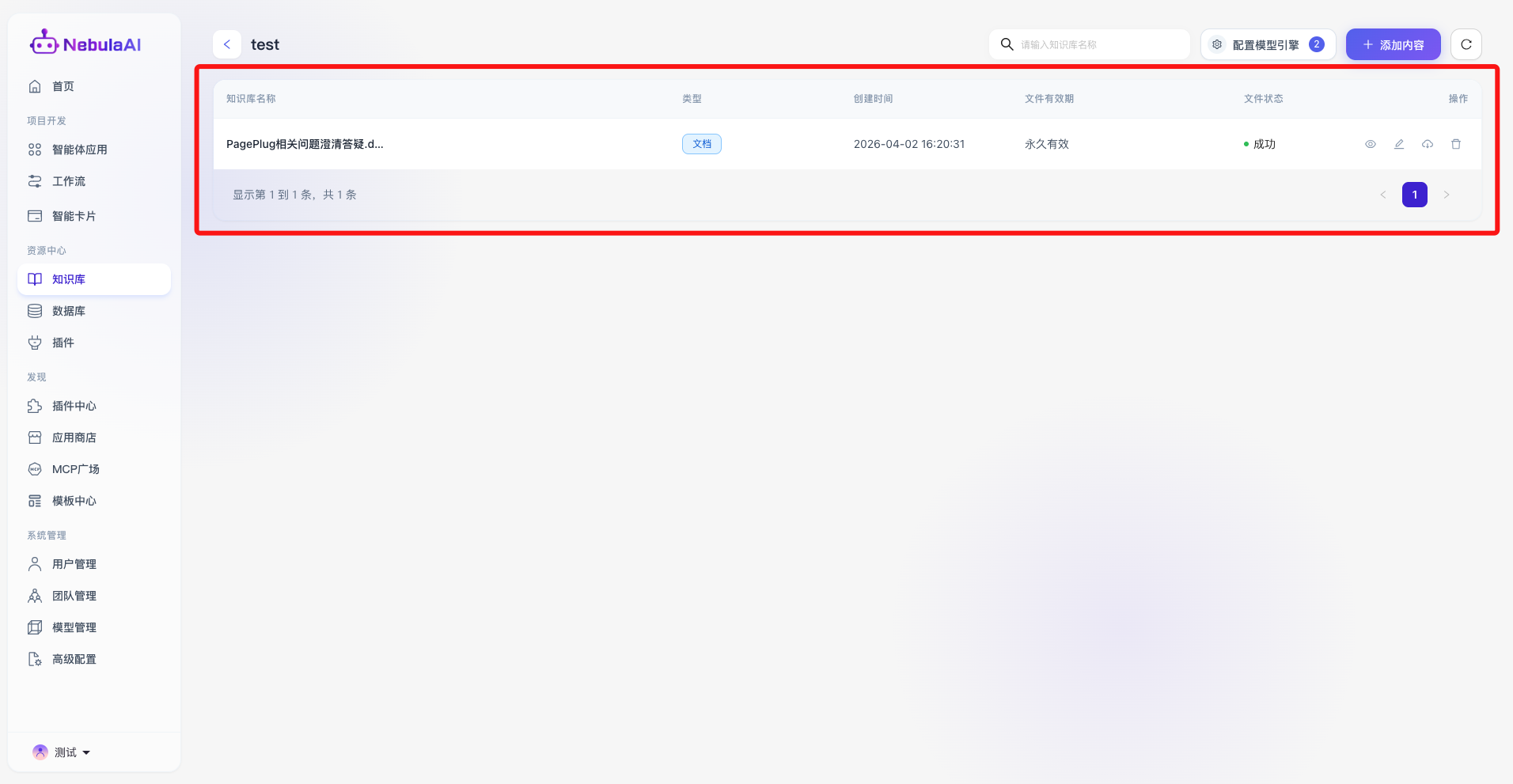
2.2 模型引擎
开发者可在此为知识库装配最契合当前业务诉求的 RAG(检索增强生成)模型。
- 向量模型:
功能价值:该模型的参数量级与维度直接决定了系统对知识库语义理解的细腻程,强大的大型向量模型能够跨越表面字词的匹配局限,深刻理解同义词、行业黑话乃至复杂长从句的潜在语义联系。
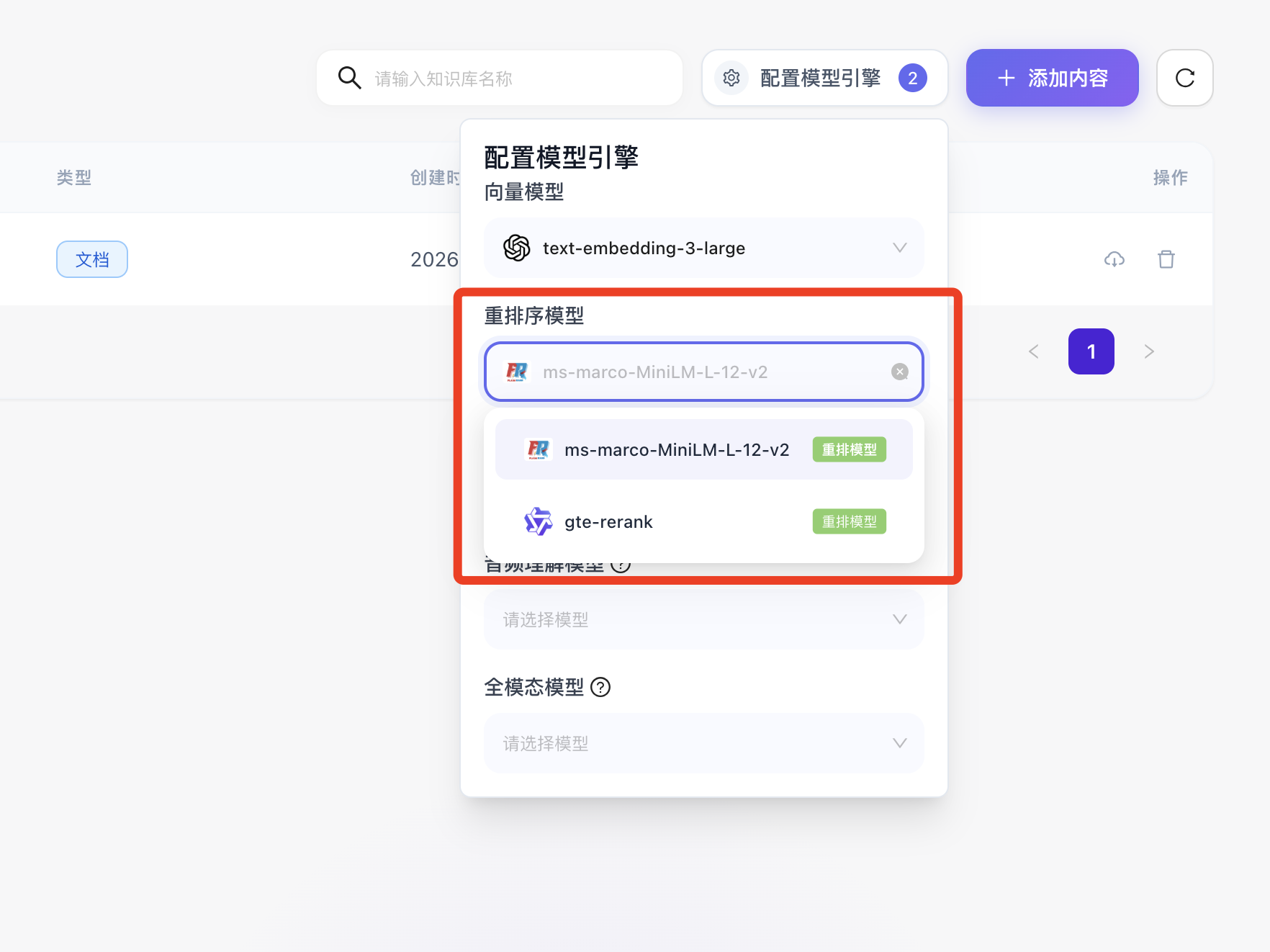
- 重排序模型:
功能价值:它会将用户的具体提问与初步召回的多个文本片段进行深度的交叉注意力机制计算,重新对匹配度进行苛刻排序,它能有效剔除“含有相似关键字但逻辑无关”的干扰信息,极大提升最终投喂给大语言模型的上下文信噪比。
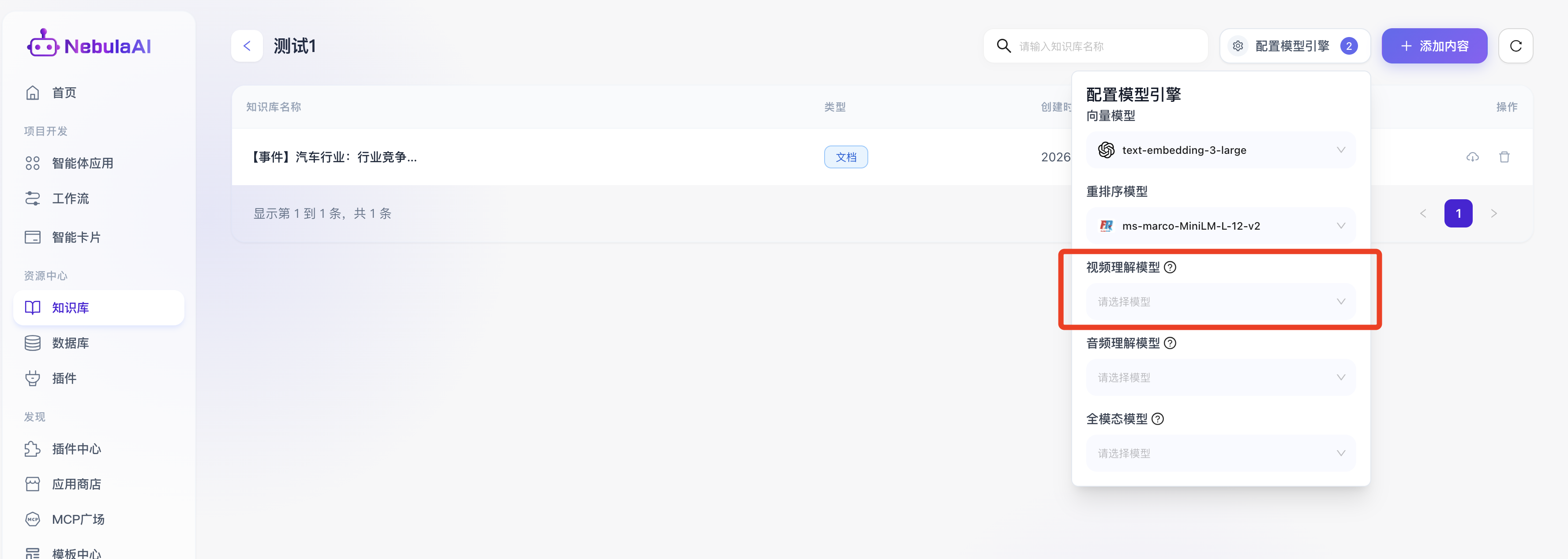
- 视频理解模型
功能价值:该模型能够“看懂”企业上传的培训录像流、复杂的工艺操作视频等,提取画面中的非结构化关键行为并进行向量结构化入库,实现从“文”到“视”的跨模态数据理解与提问解答。
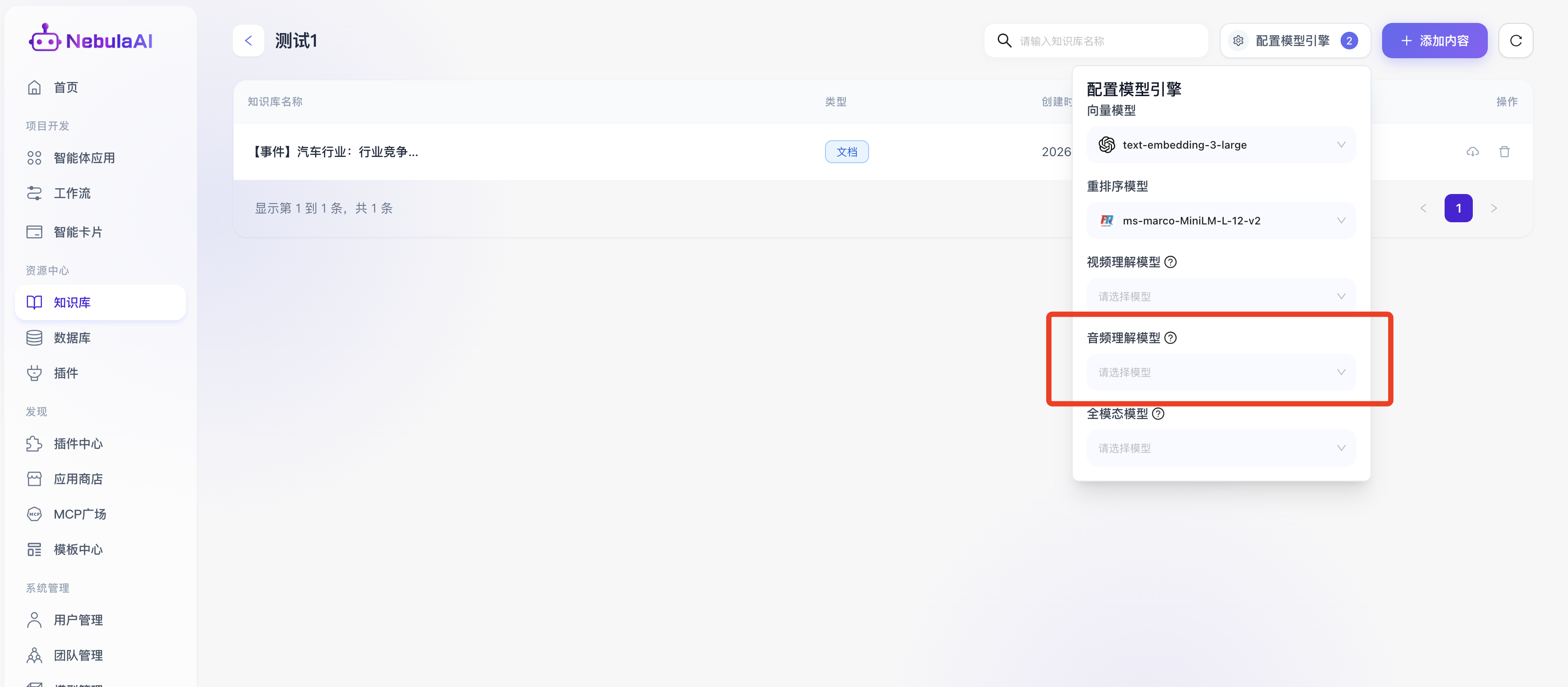
- 音频理解模型
功能价值:支配配置复杂语音频段进行深度特征提取与语义降维的专用引擎,能涵盖高精度的流式 ASR(自动语音识别转写),更包含对声音情绪波动、语调变化及说话人角色的深度分离理解。
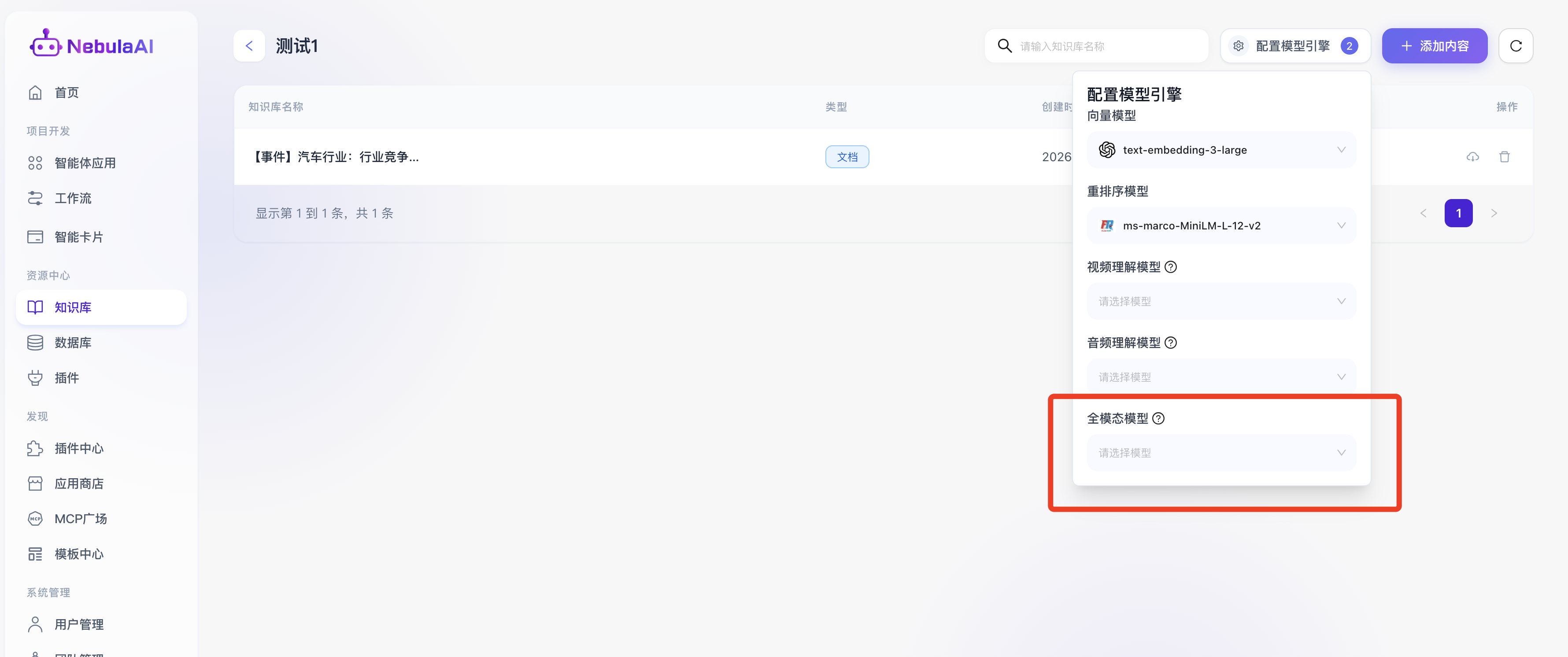
- 全模态模型
功能价值:可以不再依赖于单模态模型的拼凑式处理,而是具备像人类一样同时综合统筹“声、视、图、文”多元关联信息的能力,在面对含有语音解说、动态图表、繁杂数据的综合性报告库时,能提供降维打击级别的全局语义认知和精准答复。
3. 添加内容-导入文本文档数据
为了保障高质量的数据切分与向量化效果,平台设计了严谨的三步导流解析向导(① 添加内容 -> ② 解析设置 -> ③ 分段预览)。
有效期安全控制 :平台支持灵活的生命周期管理,提供 “永久有效” 与 “自定义有效期” 两种模式。
- 功能价值: 针对企业临时性活动说明、限时政策或季度性财报等具有严格时效性的文件,开发者可精细化设定存活周期。到期后数据自动实现检索隔离,确保智能体输出的时效性与准确性。
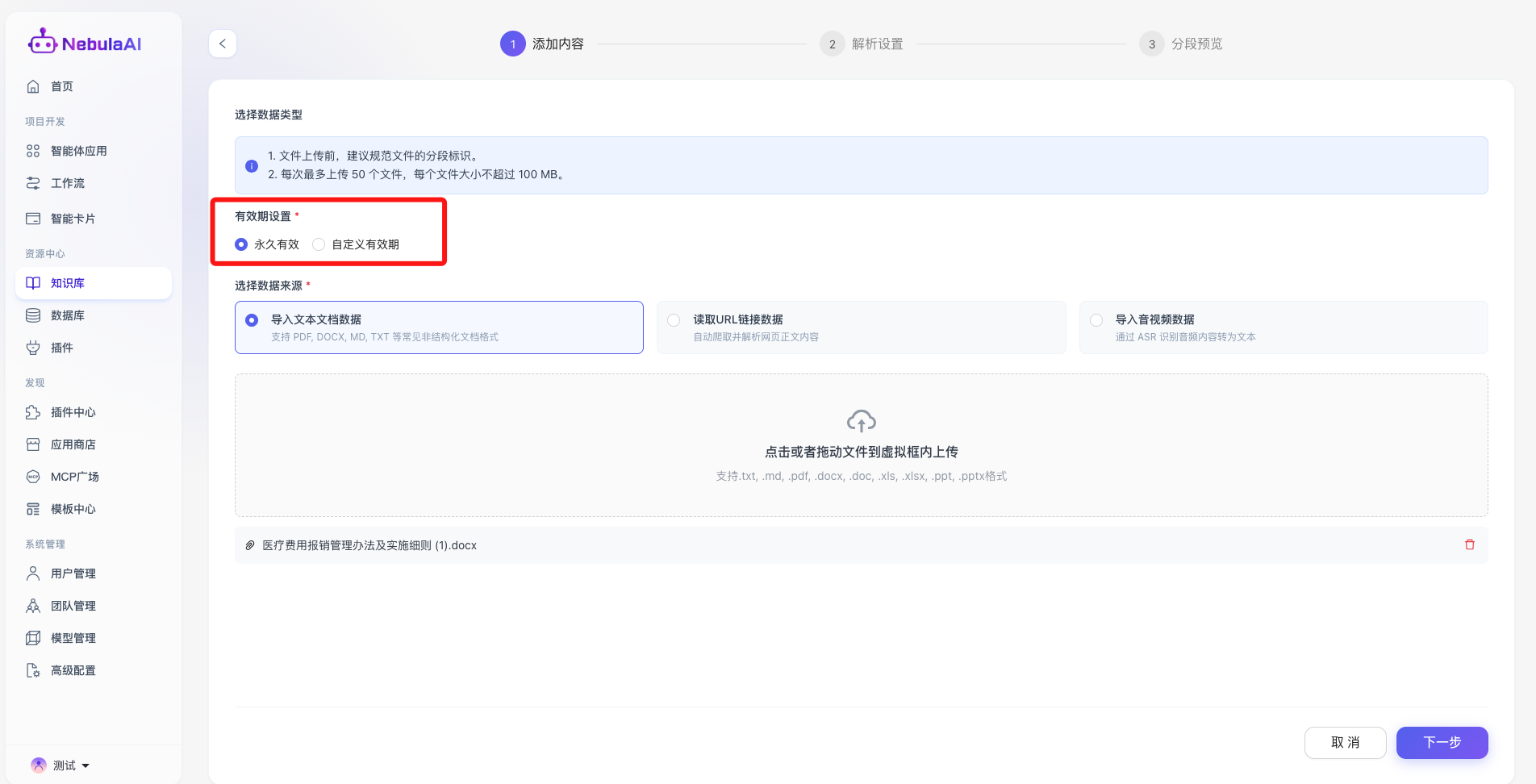
3.1 导入文本文档数据
- 格式全覆盖: 深度兼容全系企业级办公与非结构化文档,无缝支持 .txt, .md, .pdf, .docx, .doc, .xls, .xlsx, .ppt, .pptx 等主流格式。
- 极简交互与高并发: 支持可视化拖拽上传。系统具备强大的批处理能力,每次操作最多支持并行上传 50 个文件,单一文件大小支持最高 100MB 的宽容度。
- 功能价值: 极大地降低了企业存量数据资产(如操作手册、规章制度、产品白皮书)的数字化迁移门槛。
3.2 解析设置
当数据来源选择为“导入文本文档数据”时,平台提供了工业级的文档解析引擎与细粒度的文本切片机制。通过科学配置解析与分段策略,开发者能够最大化地保留非结构化文档的语义完整性与层级逻辑,从而为大语言模型提供最精准的上下文支撑。
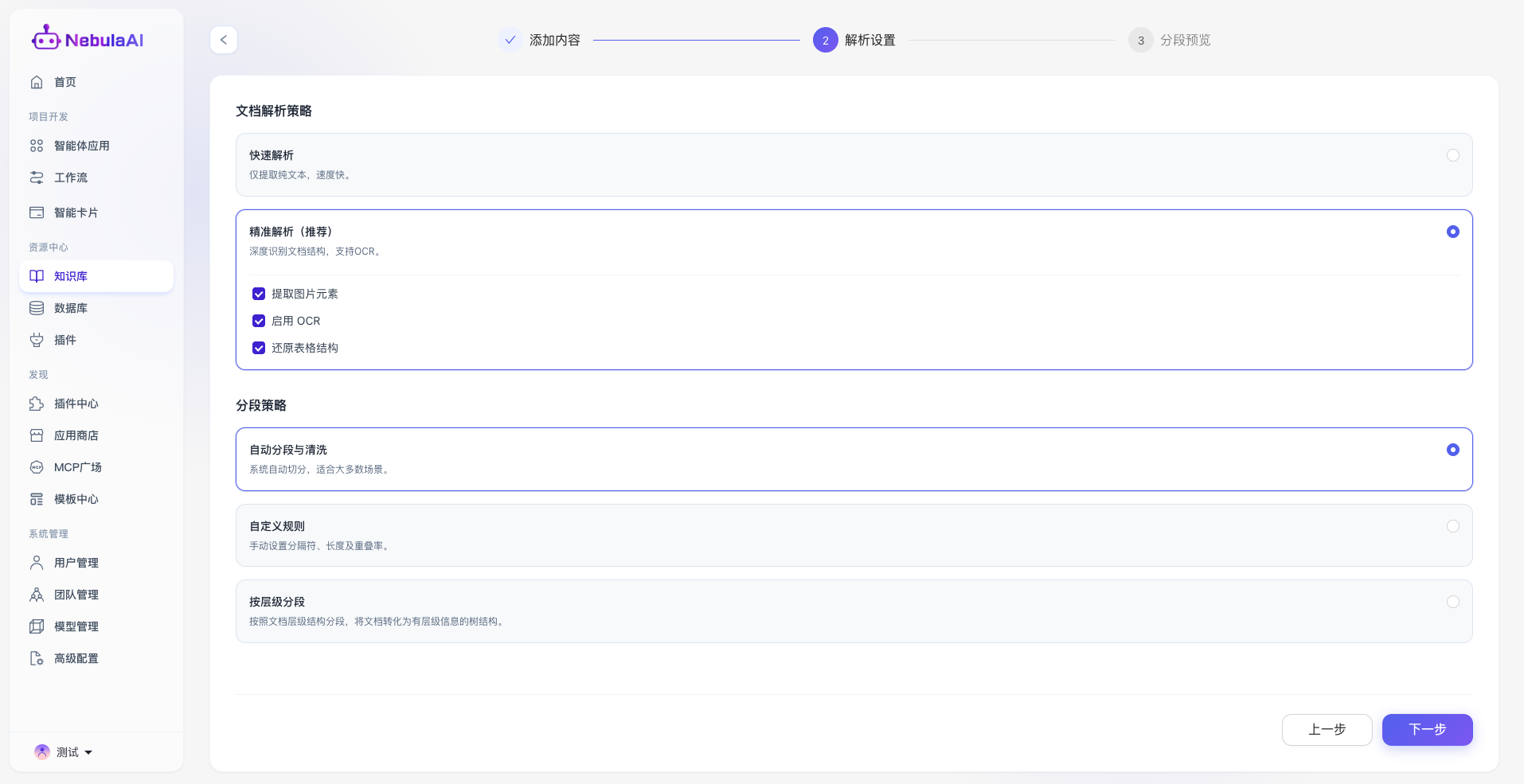
3.2.1 文档解析策略配置
该部分用于定义底层引擎读取和提取原始文档内容的方式。系统提供两种解析模式,以满足不同业务场景对解析速度与深度的需求。
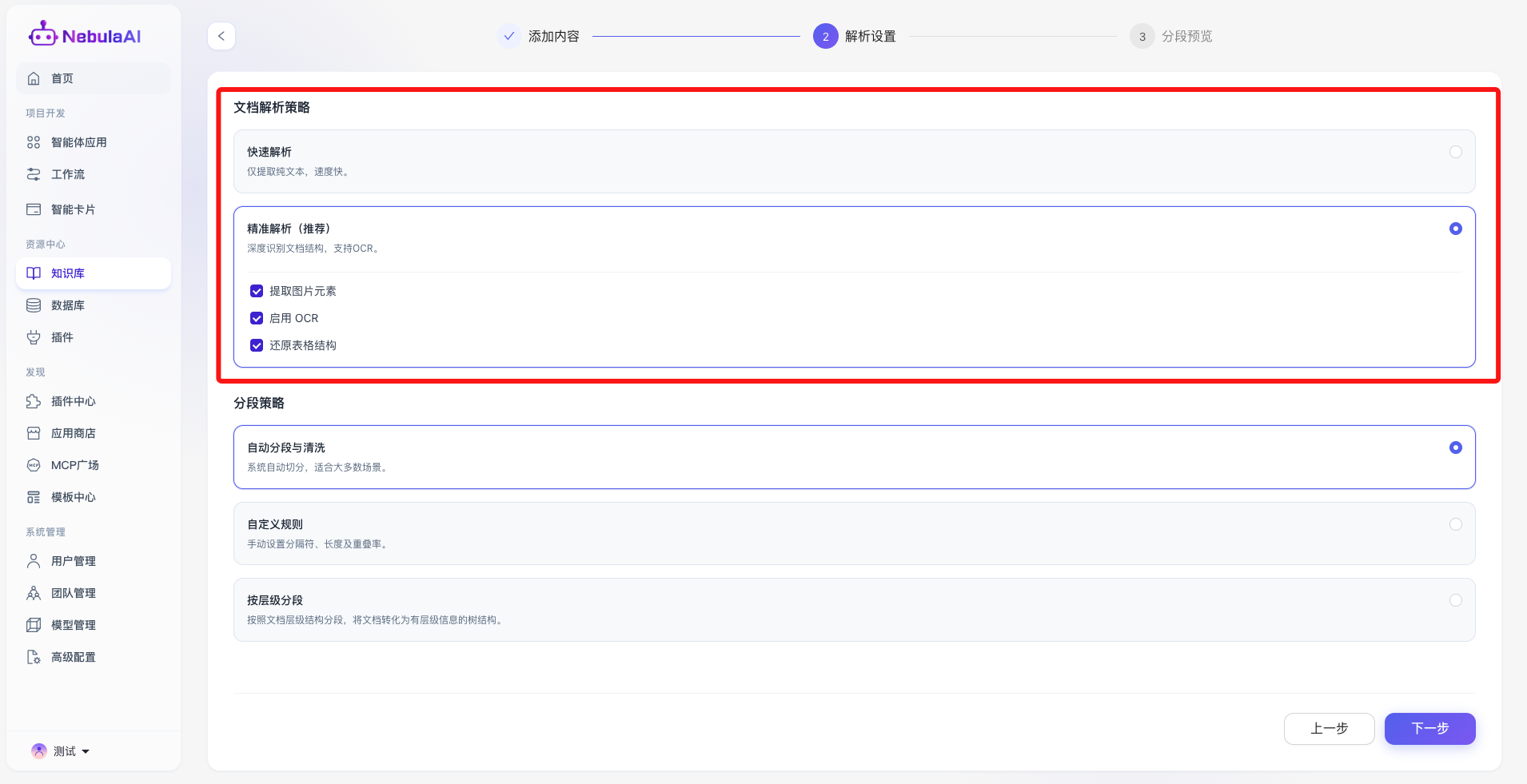
1、快速解析:
- 功能描述: 系统采用轻量级提取算法,仅剥离并提取文档中的纯文本信息,忽略复杂的排版与多媒体元素。
- 功能价值: 具备极高的处理并发率与解析速度,完美适用于内容结构单一、纯文本为主的文档(如 TXT 记事本、简单的无图排版文档),快速完成海量数据的初步入库。
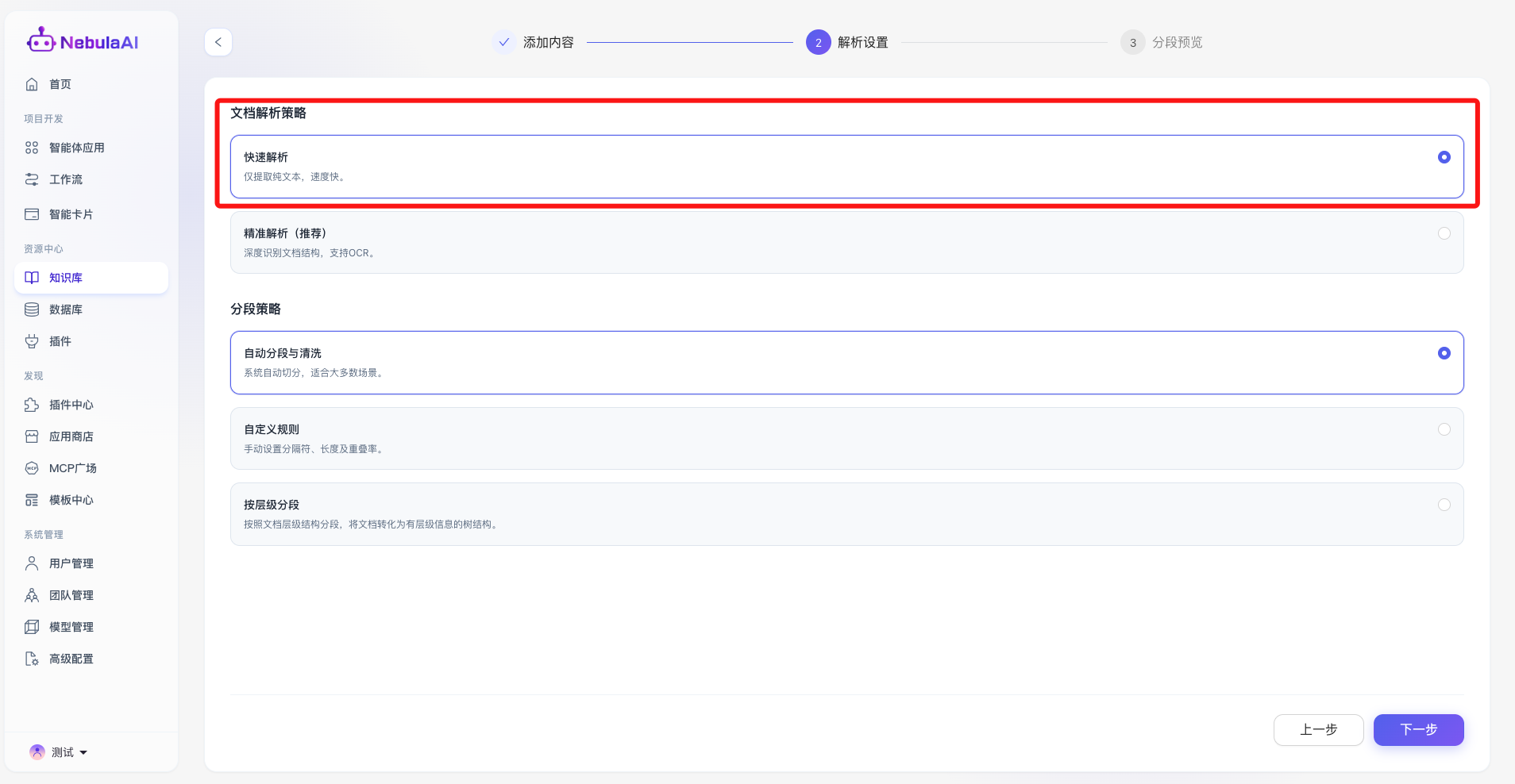
2、精准解析
- 功能描述: 启用平台自研的多模态深度解析引擎,能够精准识别并还原复杂文档(如 PDF、Docx)的排版结构。支持以下高级扩展开关:
- 提取图片元素: 自动剥离文档中的插图等视觉元素。
- 启用 OCR(光学字符识别): 针对扫描版 PDF 或图片格式的文档,利用强大的 OCR 技术将其转化为可检索的机器编码文本。
- 还原表格结构: 深度解析并保留文档中原生表格的行列二维关系,避免表格数据在文本化过程中发生错位或语义乱序。
- 功能价值: 极大提升了对企业级复杂办公文档的兼容性与解析精度,确保“脏数据”或“死数据”(如扫描件)也能转化为高质量的知识资产。
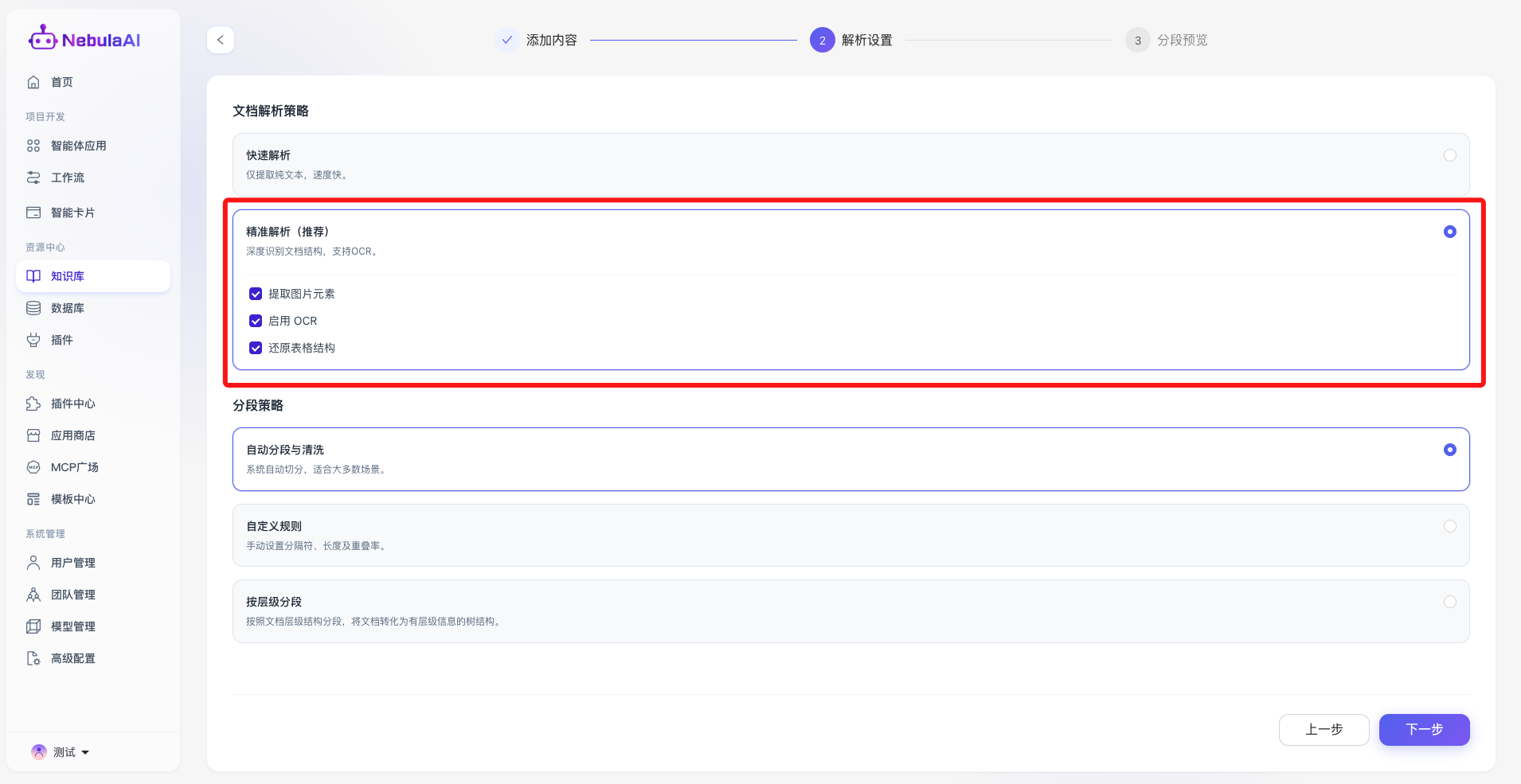
3.2.2 分段策略
文本分段(Chunking)是将长文档切割为适合向量模型处理的文本块的过程。合理的切分逻辑能有效避免语义截断,提升大模型的回答质量。
1、自动分段与清洗:
- 功能描述: 由 NebulaAI 底层算法接管,根据常见自然语言的段落特征与标点符号,自动进行文本切分与基础的数据清洗(如去除冗余空格、乱码)。
- 功能价值: “开箱即用”的智能托管模式,极大降低了非专业开发者的操作门槛,适用于 80% 以上的标准通用文档场景。
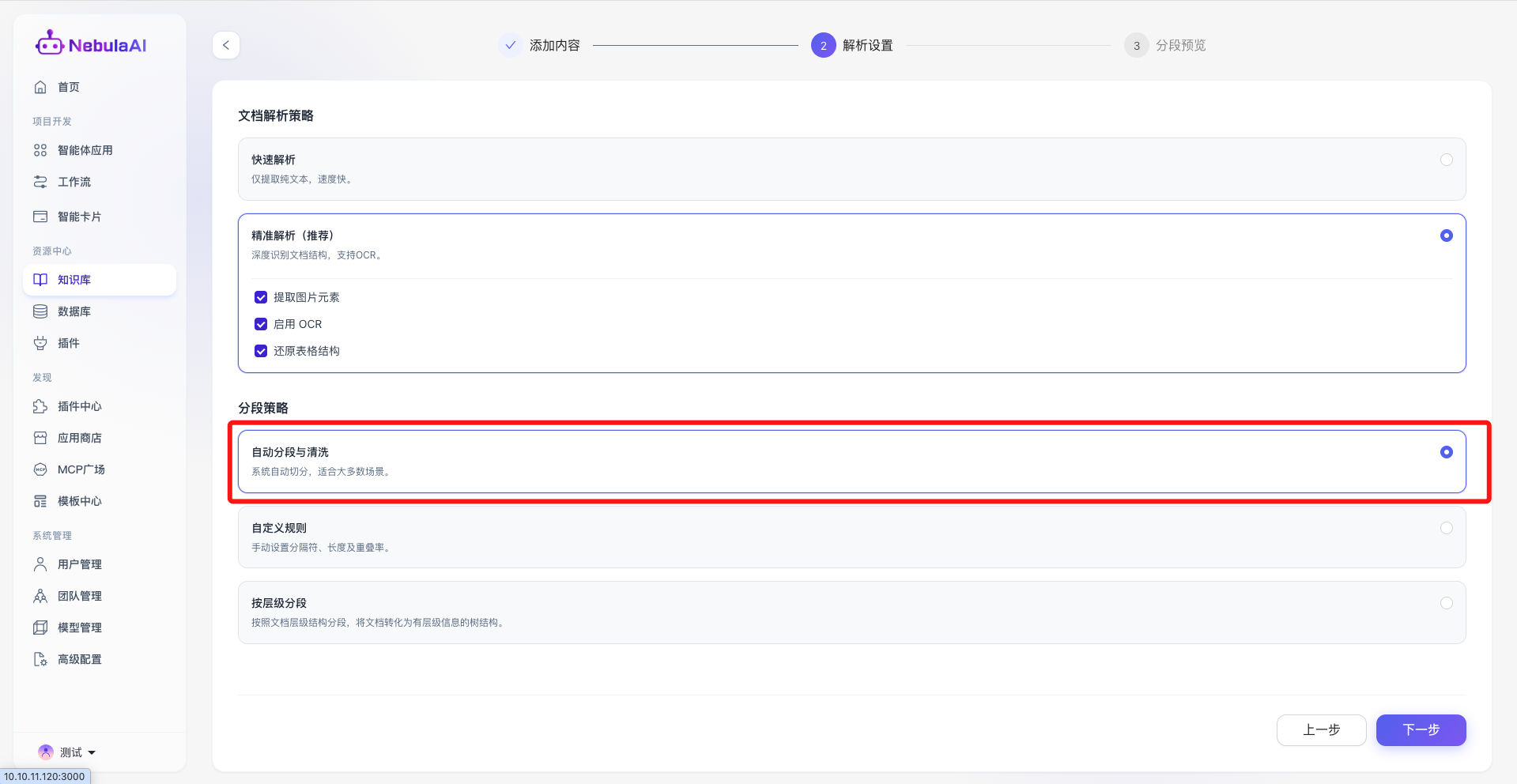
2、自定义规则:
- 功能描述: 为高级开发者提供的精细化控制面板,支持手动定义文本切片的物理边界。包含三大核心参数:
- 分段标识符: 支持指定 换行符 (\n)、双换行 (\n\n) 或 句号 (.) 作为强制切分锚点,确保切分动作符合特定文档的排版习惯。
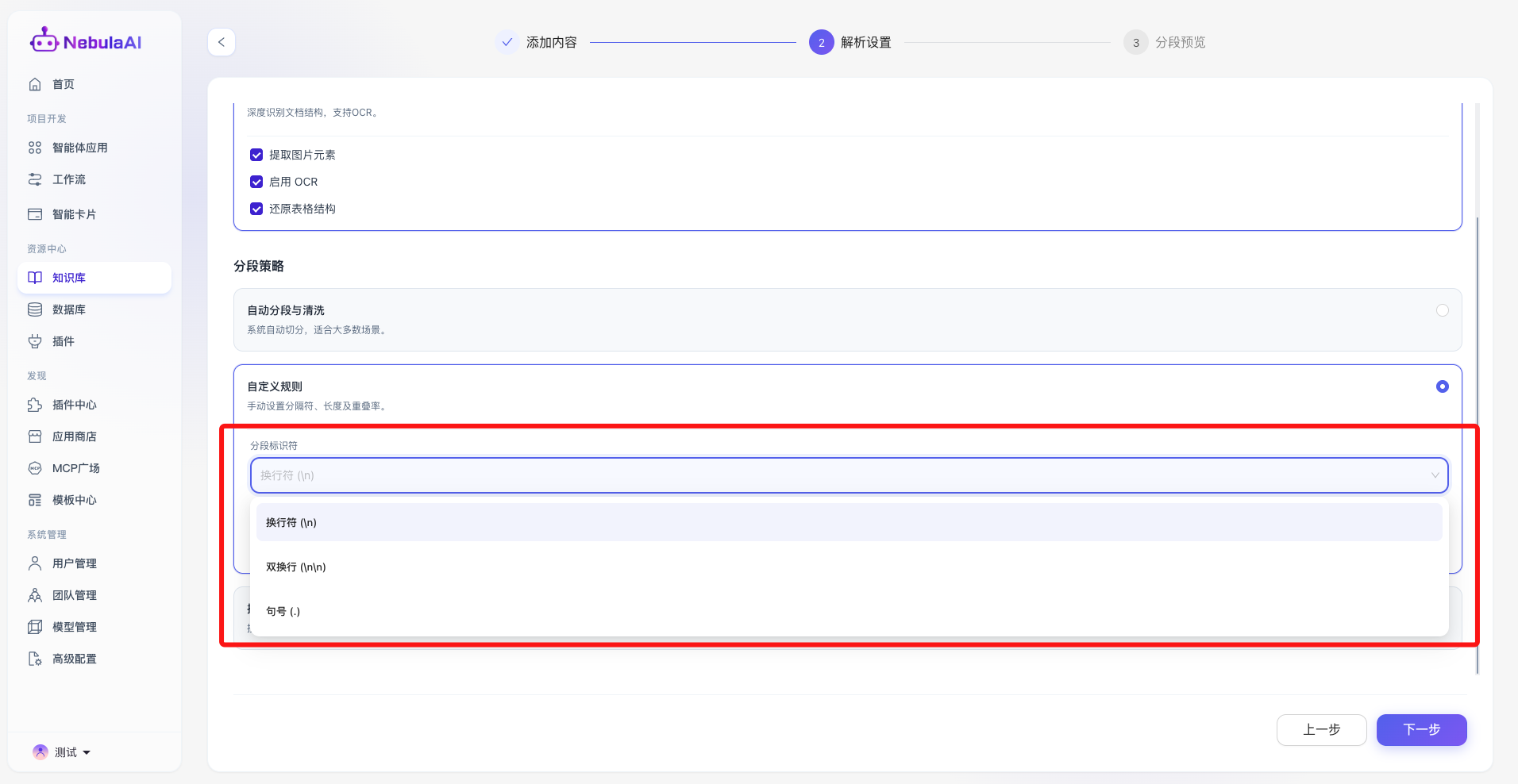
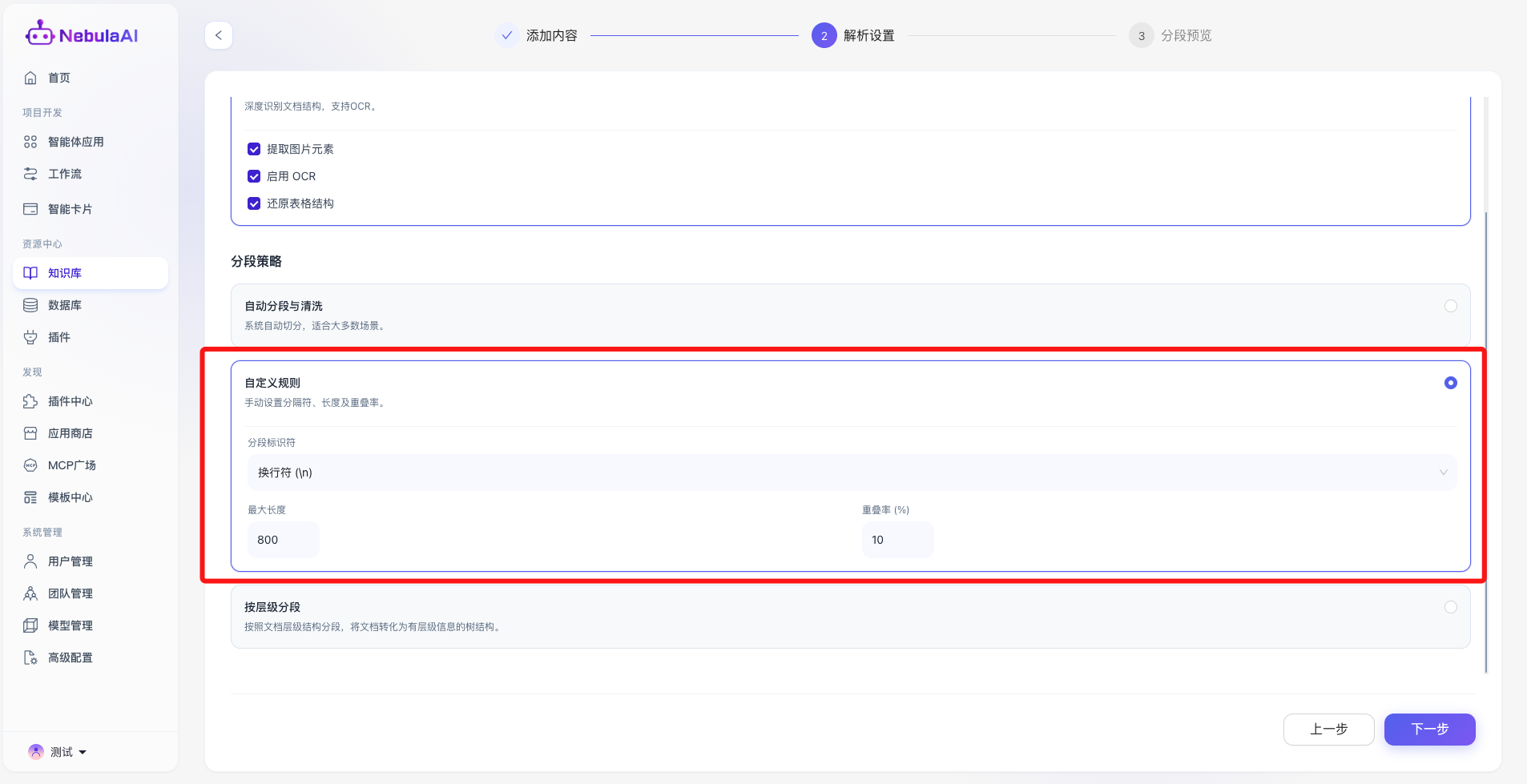
- 功能价值: 赋予开发者极致的调优自由度。特别是“重叠率”的设计,能够有效解决因硬性切断导致的“上下文语义丢失”问题,确保跨段落的核心知识点依然能在检索时被完整召回。
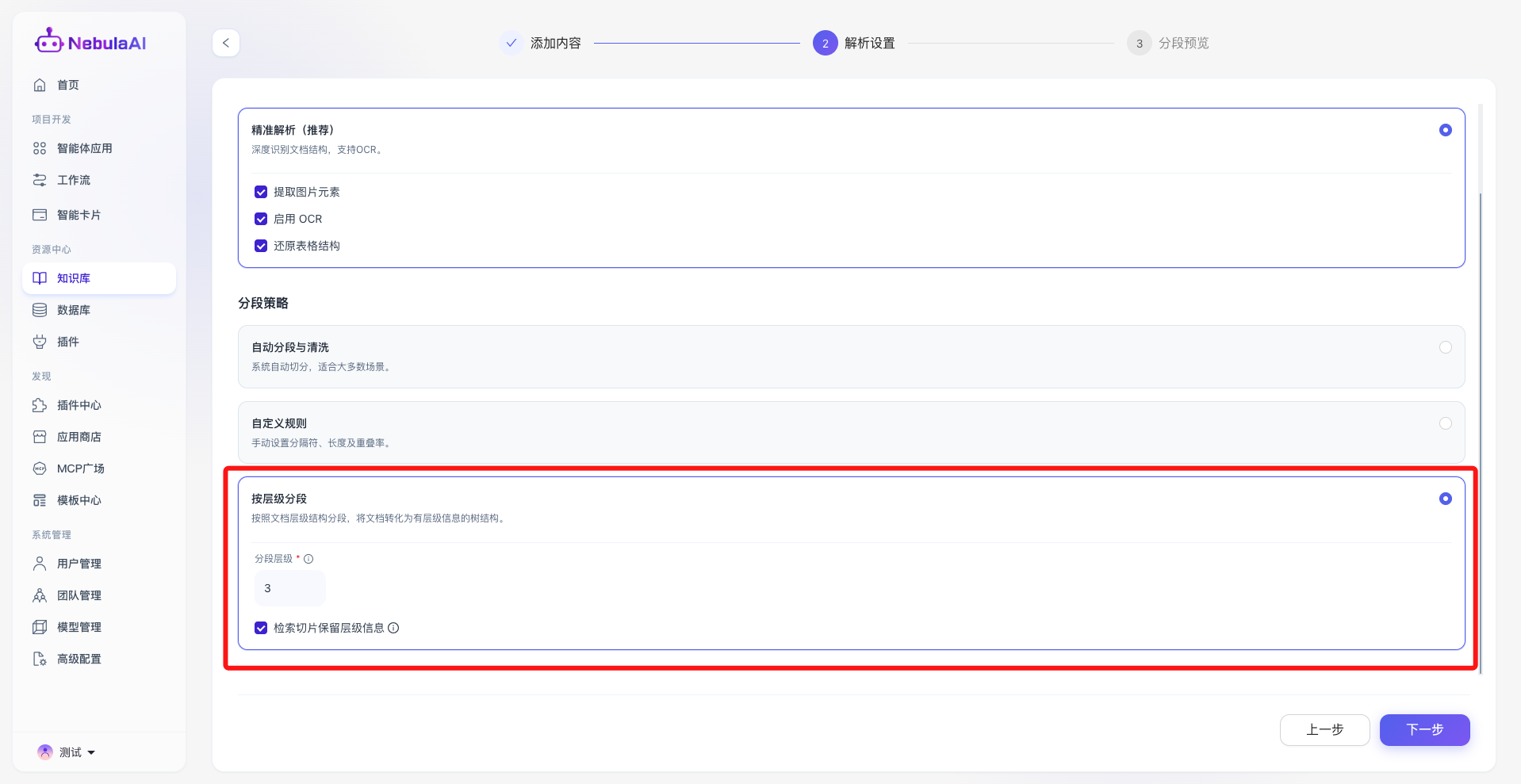
3、按层级分段:
- 功能描述: 基于文档原生的标题体系(如 Heading 1, Heading 2 等)进行语义级别的树状结构切分。
- 分段层级: 设定系统向下钻取解析的标题深度(如图示 3,即解析至三级标题)。
- 检索切片保留层级信息: 开启后,每一个切片都会自动附带其在原文档中的“祖先级”标题路径(例如:第一章 总则 -> 第一条 目的 -> [具体切片内容])。
- 功能价值: 专为法律法规、规章制度、产品白皮书等具备极强逻辑结构的文档打造。保留层级信息能让大模型在检索到碎片信息时,立刻知晓该信息的“宏观位置与前提条件”,彻底杜绝断章取义式的错误回答。
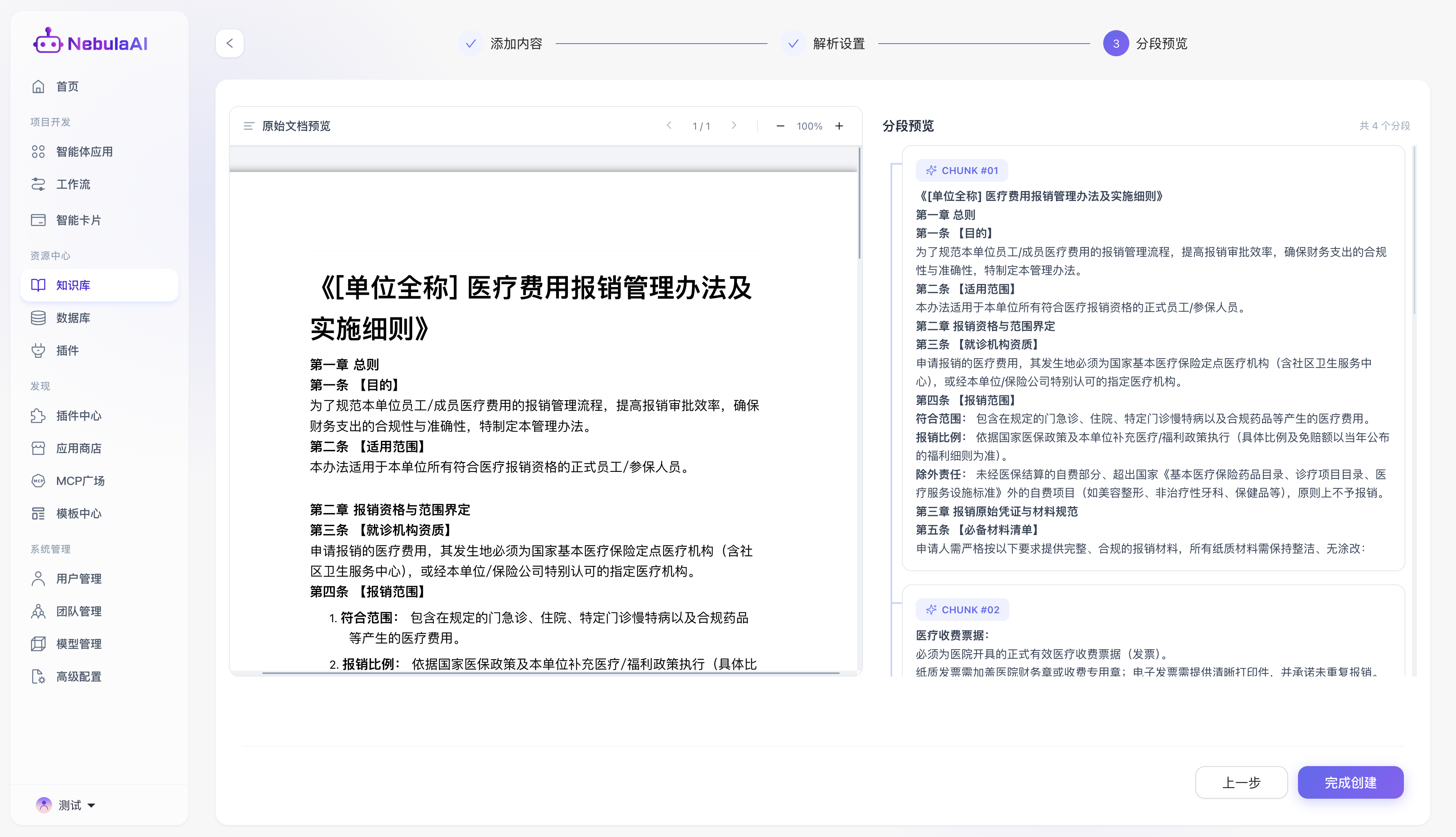
3.3 分段预览
- 功能描述: 在正式执行向量化入库前,系统提供的“所见即所得”的数据质检工作台。
- 交互体验: 界面采用左右双栏设计。左侧展示原始文档内容的结构化视图,右侧实时渲染按照上述策略切分后生成的最终 Chunk(切片)列表(如 CHUNK #01, CHUNK #02)。
- 功能价值: 开发者可以在正式消耗大模型算力与入库前,直观地核验切分粒度是否合理、段落语义是否连贯、表格或层级是否被破坏。如发现切分不佳,可随时点击“上一步”回退调整参数,形成业务闭环,全面保障注入智能体大脑的知识质量。
4. 读取URL链接数据
4.1 读取URL
- 功能特性: 支持批量输入 Web 站点的 URL 地址,依托底层强大的自动化爬虫引擎,直接解析网页正文内容并剔除冗余 HTML 标签(单次最高支持批量解析 10 个 URL)。
- 业务场景与价值: 完美适用于接入企业官网的帮助中心、实时更新的行业维基 (Wiki) 或飞书/语雀等在线文档。该功能打破了静态文件的壁垒,确保智能体能够掌握业务线最新、最实时的动态知识,大幅降低人工维护文档的成本。
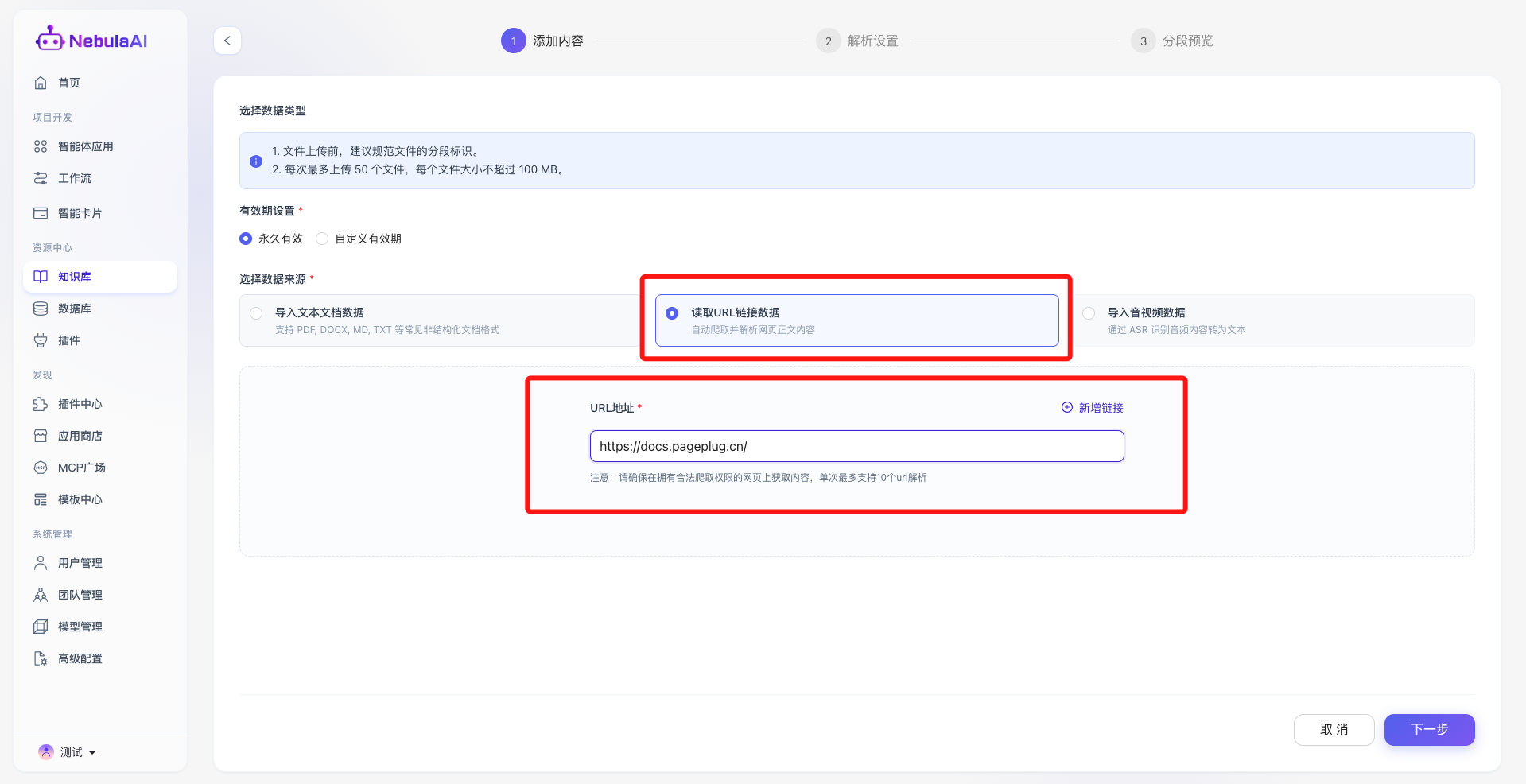
4.2 解析设置
当数据来源选择为“通过URL获取诗句”时,平台提供了工业级的文档解析引擎与细粒度的文本切片机制。通过科学配置解析与分段策略,开发者能够最大化地保留非结构化文档的语义完整性与层级逻辑,从而为大语言模型提供最精准的上下文支撑。
4.2.1 文档解析策略配置
该部分用于定义底层引擎读取和提取原始文档内容的方式。系统提供两种解析模式,以满足不同业务场景对解析速度与深度的需求。
4.2.2 分段策略
文本分段(Chunking)是将长文档切割为适合向量模型处理的文本块的过程。合理的切分逻辑能有效避免语义截断,提升大模型的回答质量。
1、自动分段与清洗:
- 功能描述: 由 NebulaAI 底层算法接管,根据常见自然语言的段落特征与标点符号,自动进行文本切分与基础的数据清洗(如去除冗余空格、乱码)。
- 功能价值: “开箱即用”的智能托管模式,极大降低了非专业开发者的操作门槛,适用于 80% 以上的标准通用文档场景。
2、自定义规则:
- 功能描述: 为高级开发者提供的精细化控制面板,支持手动定义文本切片的物理边界。包含三大核心参数:
- 分段标识符: 支持指定 换行符 (\n)、双换行 (\n\n) 或 句号 (.) 作为强制切分锚点,确保切分动作符合特定文档的排版习惯。
- 功能价值: 赋予开发者极致的调优自由度。特别是“重叠率”的设计,能够有效解决因硬性切断导致的“上下文语义丢失”问题,确保跨段落的核心知识点依然能在检索时被完整召回。
3、按层级分段:
- 功能描述: 基于文档原生的标题体系(如 Heading 1, Heading 2 等)进行语义级别的树状结构切分。
- 分段层级: 设定系统向下钻取解析的标题深度(如图示 3,即解析至三级标题)。
- 检索切片保留层级信息: 开启后,每一个切片都会自动附带其在原文档中的“祖先级”标题路径(例如:第一章 总则 -> 第一条 目的 -> [具体切片内容])。
- 功能价值: 专为法律法规、规章制度、产品白皮书等具备极强逻辑结构的文档打造。保留层级信息能让大模型在检索到碎片信息时,立刻知晓该信息的“宏观位置与前提条件”,彻底杜绝断章取义式的错误回答。
5. 导入音视频数据
5.1 导入音视频数据
- 功能特性: 突破单纯的文本检索限制,平台内置先进的 ASR(自动语音识别)引擎,支持将海量多媒体文件高精度转化为结构化文本知识。
- 多格式兼容:
- 音频阵列: 涵盖 .mp3, .wav, .wma, .ogg, .aac, .flac 等录音及高保真音频格式。
- 视频阵列: 涵盖 .mp4, .avi, .mkv, .mov, .flv 等各类高频视频封装格式。
- 超大容量支持: 单一多媒体文件支持高达 500MB 的超大容量上传。
- 功能价值: 彻底激活企业的“暗数据”。无论是长达数小时的内部培训视频、高管会议录音,还是客服中心的客户通话录音,均可一键上传并转化为智能体的核心知识储备,实现多模态数据的深度价值挖掘。
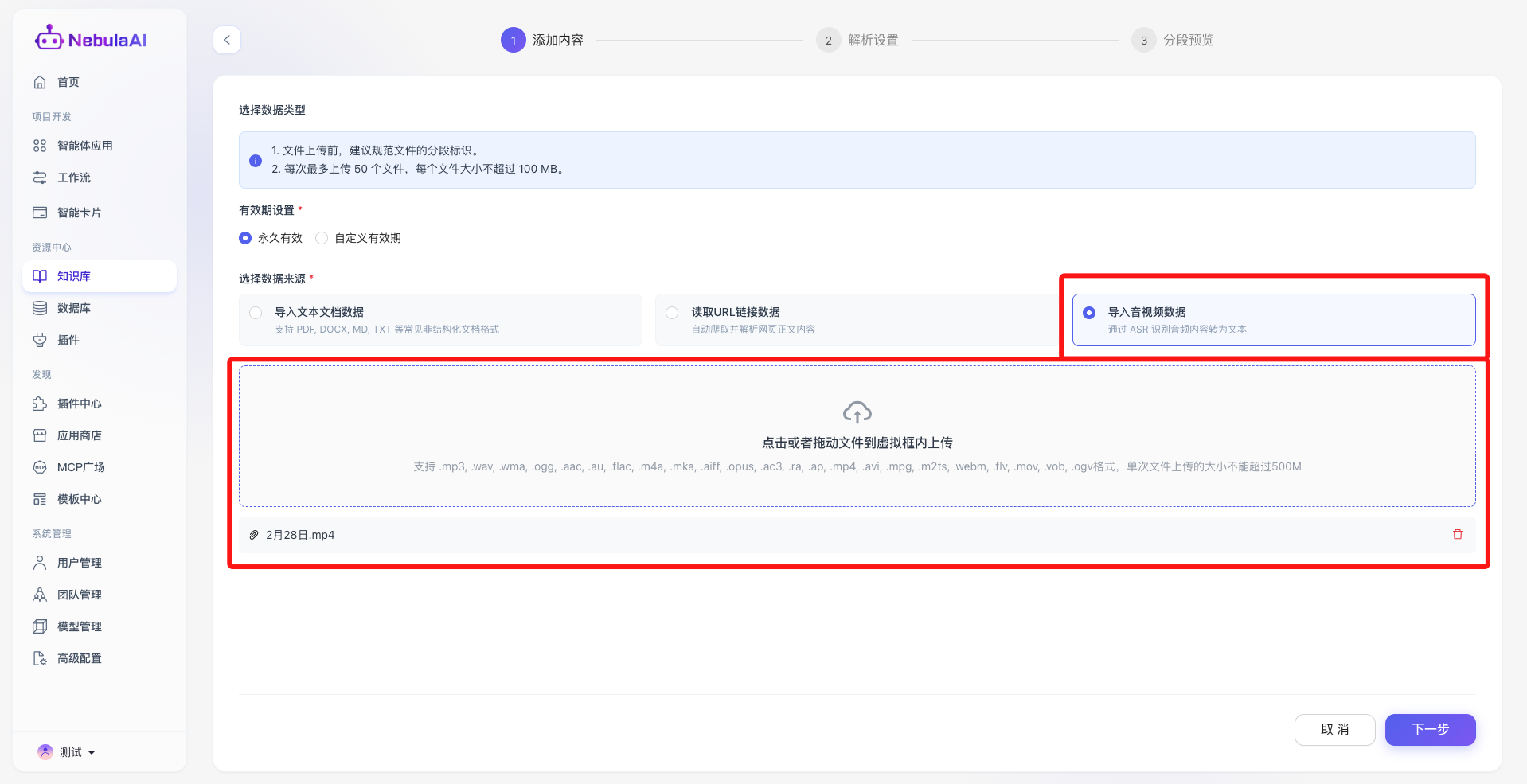
5.2 解析设置
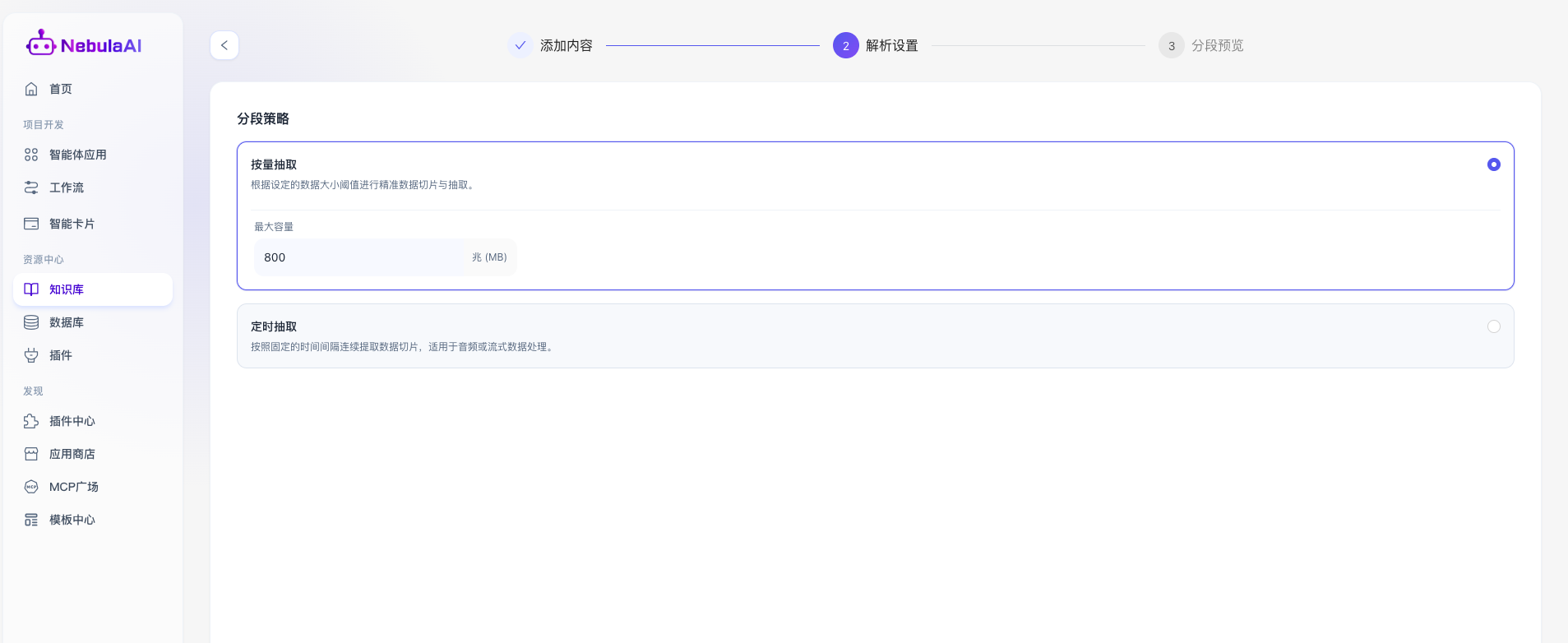
1、按量抽取:
- **功能描述: **侧重于依据数据物理存储大小的阈值进行精准的数据切片与抽取。该策略适用于对单次处理数据量有严格控制要求的场景,确保切分后的数据块符合系统底层处理与存储的最佳性能区间,包含的核心参数如下:
- **最大容量: **设定单一数据分段的体积上限(如图示 800 兆/MB ),该参数通过物理存储容量强制截断文件,确保每个切片的大小严格控制在设定的阈值范围内,这能有效避免在解析超大文件时因单片数据过大而导致的系统内存溢出(OOM)或处理超时,完美契合对文件物理体积敏感的数据入库与预处理需求。
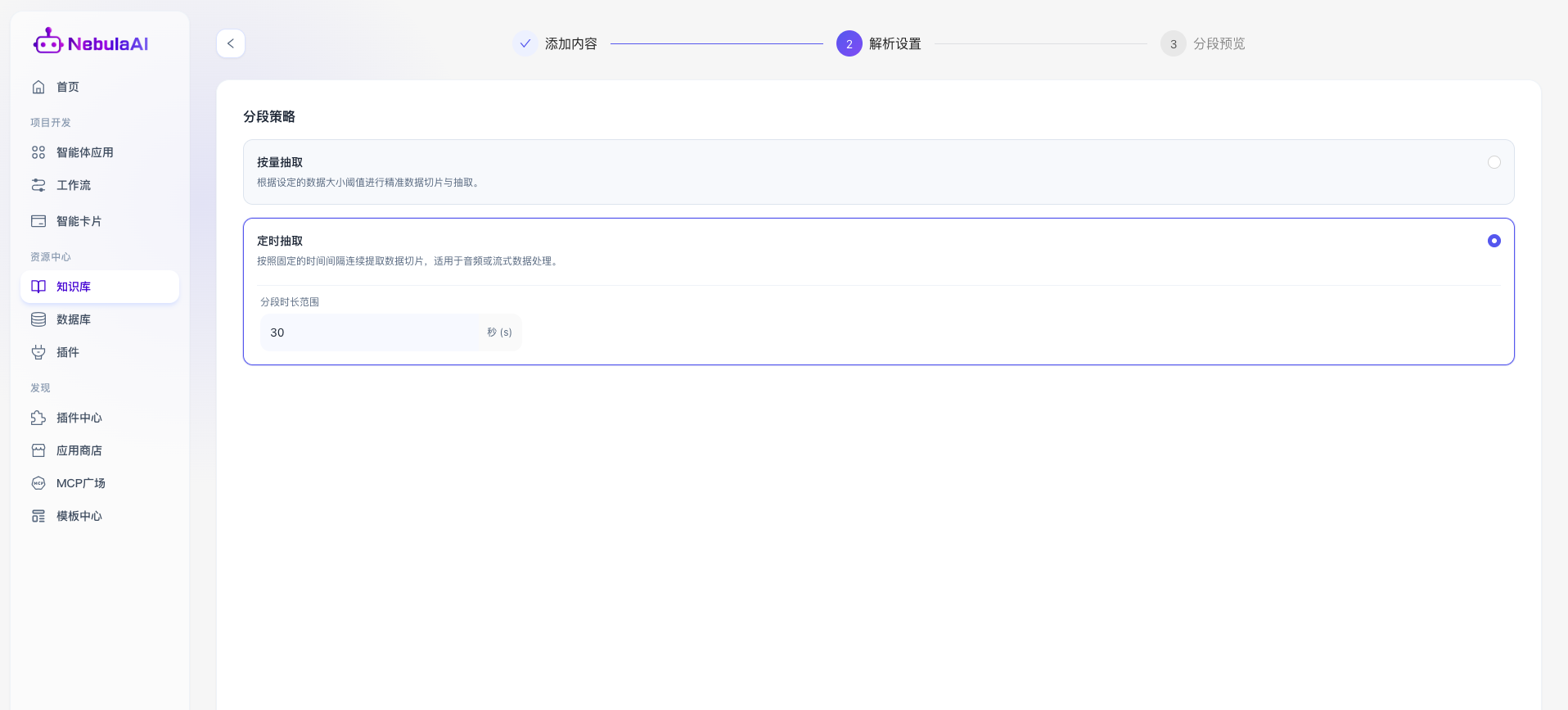
 2、定时抽取:
2、定时抽取:
- 功能描述: 侧重于依据时间维度连续提取数据切片,该策略专门针对音频、视频等多媒体文件或持续输入的流式数据而设计,通过固定的时间窗口来标准化截取数据片段。包含的核心参数如下:
- 分段时长范围: 设定单一数据分块的时间跨度(如图示 30 秒/s ),系统将严格按照设定的时间间隔,周期性地对音视频流或动态数据进行截断。这种按固定时间片切分的方式,能够为后续的语音转写(ASR)、视频关键帧提取或流式特征分析提供长度均等、标准化的输入素材,从而极大提升多媒体数据解析的连贯性与处理效率。
5.3 分段预览
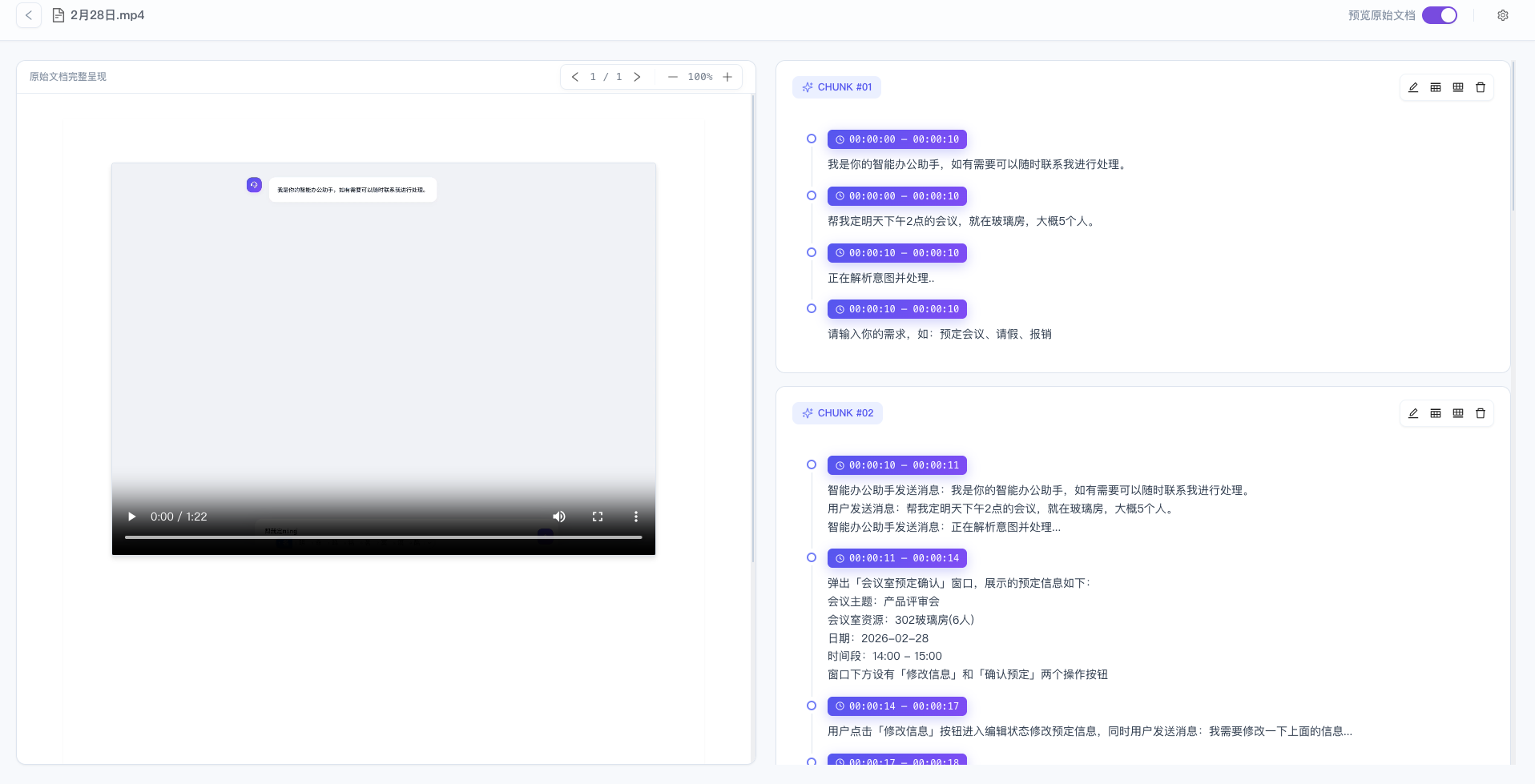
- 功能描述: 在正式将多媒体数据(如视频、音频)进行向量化入库前,系统提供的多模态数据“所见即所得”的质检与编辑工作台,该功能直观呈现了解析引擎对视频文件进行时间轴切片,并结合画面/语音提取文本内容(如对话转写、画面动作描述)的最终结果。
- 交互体验: 界面采用高效的左右联动双栏设计。
- 左侧(原始视频完整呈现): 提供内嵌的高清视频播放器,支持原文件的直接播放、进度拖拽及画面缩放,右上角设有“预览原始文档”快捷开关,方便用户随时对照原文档。
- 右侧(分段切片列表): 以结构化卡片的形式实时渲染切分生成的最终知识块(如 CHUNK #01, CHUNK #02)。每个 Chunk 内会精细标注具体的时间戳区间(如 00:00:00 - 00:00:10),并清晰展示该时段内提取的文本语义(如系统提示音、用户对话、操作动作等)。此外,每个 Chunk 卡片右上角均配备了快捷操作栏(包含编辑、查看详情、删除),支持人工干预。
- 功能价值: 为开发者构建了一道关键的数据质量防线,通过“左侧看原片,右侧核文本”的对照模式,用户可以直观地校验时间窗口切分是否合理、多模态内容的语义转换是否准确(例如:画面中弹出的会议室预定信息是否被完整提取),若发现机器识别有误或包含冗余信息,用户可直接在当前界面手动编辑修正或删除无效切片。